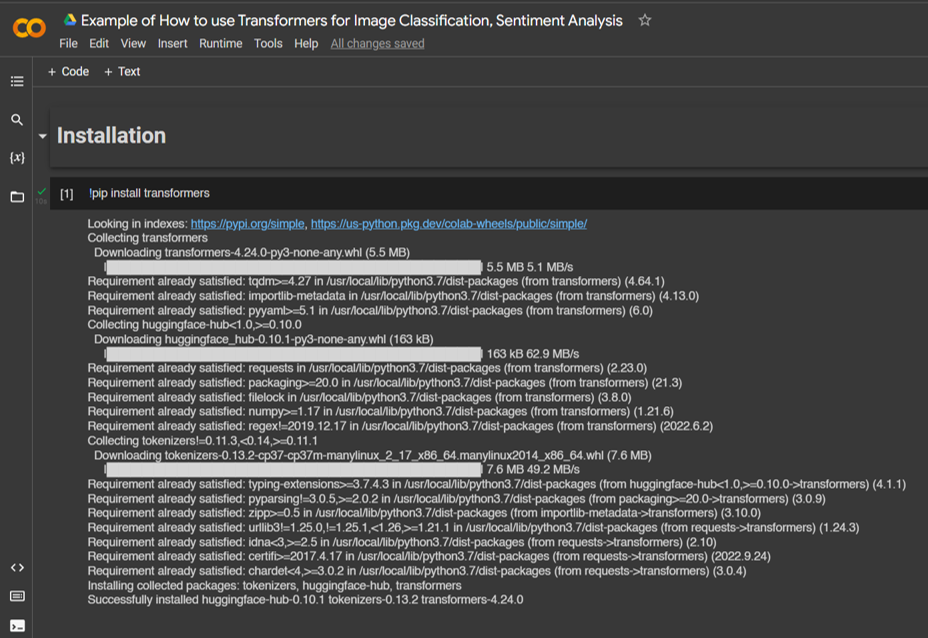
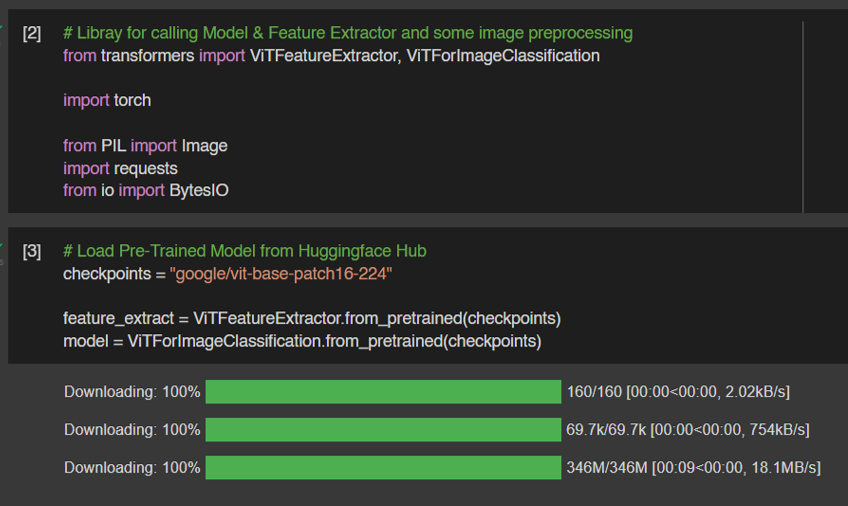
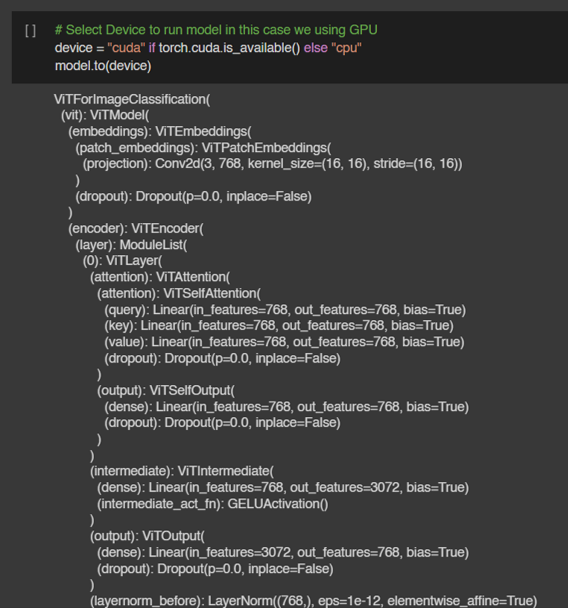
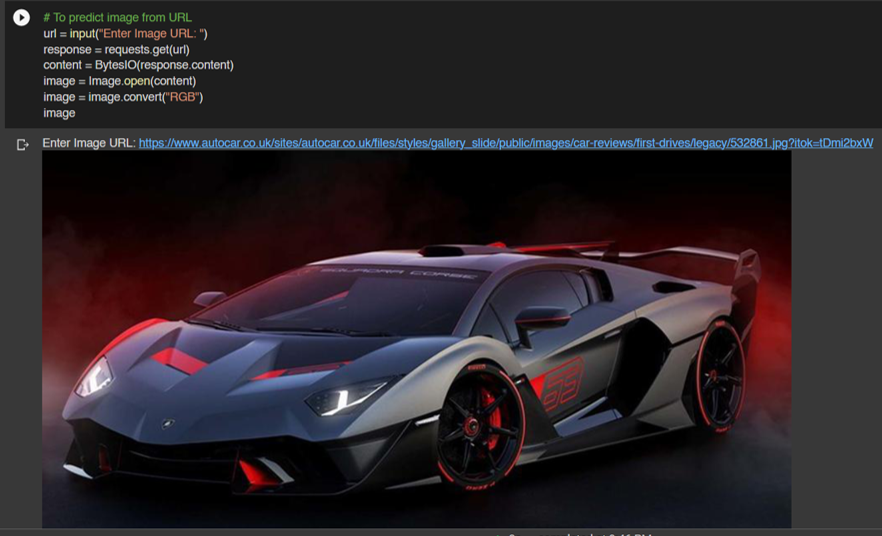
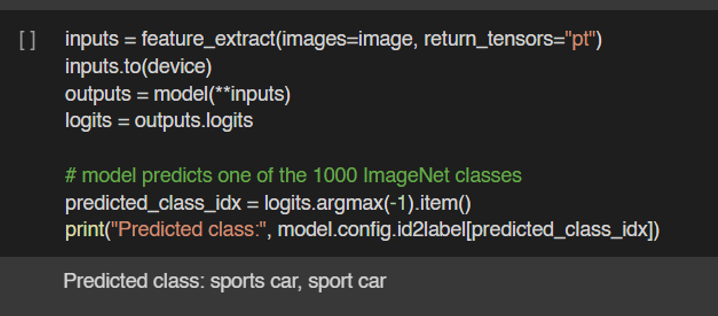
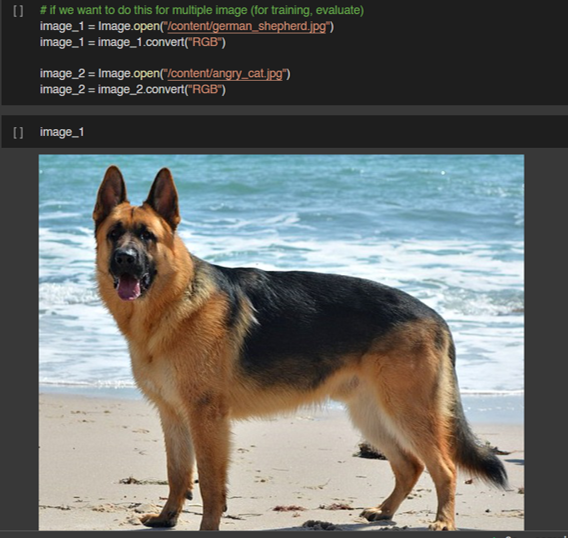
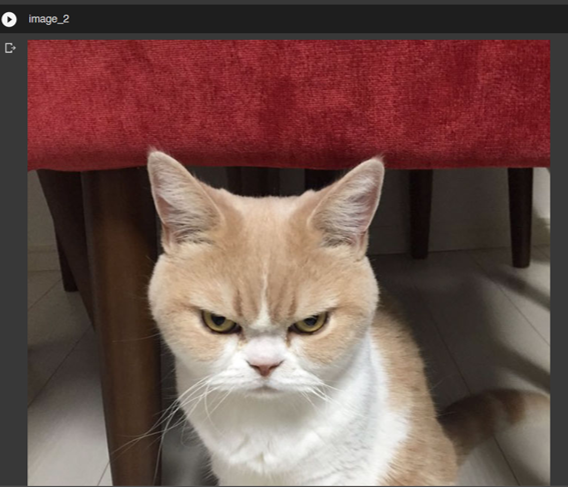
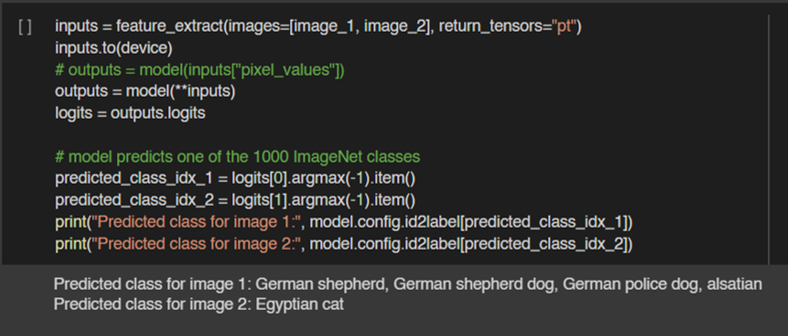
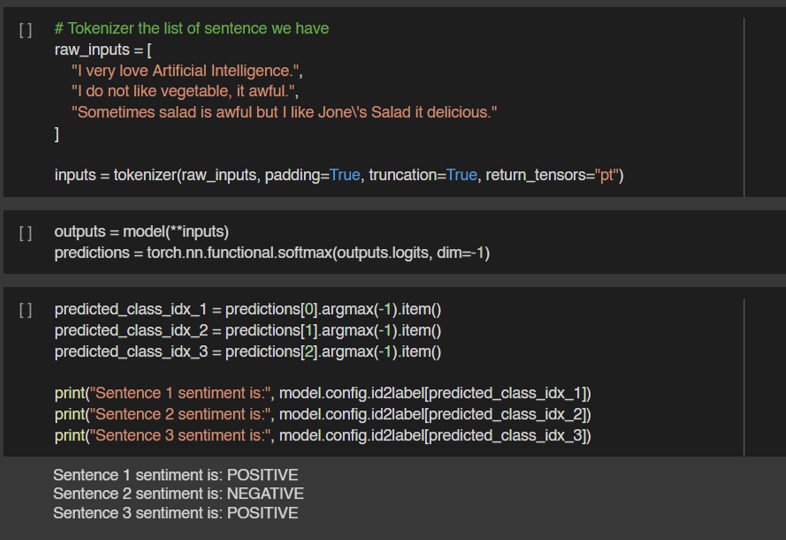

Llama 3.1 สำหรับงาน Text Classification นั้นสามารถ Fine-tuning ในรูปแบบ Supervised Finetuning ได้เช่นกัน ซึ่งจะทำให้ผลลัพธ์ดีขึ้นมากในงานนั้น

Llama 3.1 คือ Large Language Model แบบ Open Source ที่ถูกพัฒนาโดย Meta และปล่อยให้นักพัฒนานำไปใช้งานได้แบบฟรี มีเวอร์ชั่นตั้งแต่ 2, 3, 3.1

System Design คือกระบวนการออกแบบสถาปัตยกรรมและองค์ประกอบที่เกี่ยวข้องกับ Software System ให้สอดคล้องกับความต้องการของธุรกิจและผู้ใช้งาน