LLaMA 3.1 คืออะไร?

LLaMA 3.1 (Large Language Model Meta AI) คือ Large Language Model แบบ Open Source ที่ถูกพัฒนาโดย Meta และปล่อยให้นักพัฒนานำไปใช้งานได้แบบฟรี โดย Llama นั้นมีมาตั้งแต่เวอร์ชั่น 2, 3, และ 3.1 ตัวล่าสุดนี้
Llama เป็น Generative AI เช่นเดียวกันกับพวก chatGPT, Claude, Mistral ที่หน้าที่หลักคือการ Generated Text เพื่อตอบคำถามทั่วไปของมนุษย์ ความรู้เฉพาะทางด้านต่าง ๆ ช่วยแปลภาษา ไปจนถึงการช่วยเขียนโค้ด การตอบปัญหาทางคณิตศาสตร์ (ที่ถูกต้องแม่นยำและซับซ้อนยิ่งขึ้นใน 3.1) และในเชิงเทคนิค Llama คือ Transformer ส่วน Decoder ที่ปรับเปลี่ยนองค์ประกอบเพียงเล็กน้อย (ไม่ได้ใช้ Mixture of Experts แบบ Gemini) จุดหลัก ๆ ที่ปรับเปลี่ยนคือการทำ Positional Embeddings, Normalization, Attention Mechanism, Memory Efficiently, และ Activation Function รายละเอียดจะกล่าวในส่วนต่อไป
Llama 3.1 เก่งแค่ไหน?
ในการวัดผลโมเดล Llama นั้นมีด้วยกันหลัก ๆ 2 แบบคือวัดผลบนงานชุดข้อมูลด้านภาษาแบบต่าง ๆ และวัดผลโดยมนุษย์ ซึ่งจะเปรียบเทียบทั้ง 3 ขนาด (8B, 70B, 405B) ของโมเดล Llama 3.1 กับ โมเดล LLM ในท้องตลาดเจ้าใหญ่ ๆ โดยชุดข้อมูลของงานด้านภาษาที่วัดผลมีดังนี้
MMLU: Multi-task Language Understanding on MMLU ออกแบบมาเพื่อวัดความรู้ของโมเดลในขั้นตอนที่เป็น Pretrained (ก่อนที่จะนำไปทำ Downstream แก้ปัญหาเฉพาะทาง) โดยจะทดสอบทั้ง zero-shot และ few-shot ซึ่งจะทำให้การแก้ปัญหาของชุดข้อมูลนี้มีความท้าทายและคล้ายกับการทดสอบของมนุษย์มากยิ่งขึ้น และปัญหาจะครอบคลุมทั้งหมด 57 หัวข้อไม่ว่าจะเป็น STEM, มนุษยศาสตร์, สังคมศาสตร์, และอื่น ๆ โดยมีความยากตั้งแต่ระดับพื้นฐานไปจนถึงระดับมืออาชีพขั้นสูงครอบคลุมทั้งความรู้ทั่วไปรอบโลกไปจนถึงการแก้ปัญหาทั้งในโจทย์คณิตศาสตร์ ประวัติศาสตร์ และความรู้เฉพาะทางอย่างกฎหมายและจริยธรรม
ด้านความเข้าใจภาษาทั่วไป
- MMLU PRO: เป็นชุดข้อมูลทดสอบเช่นเดียวกันกับ MMLU แต่เพิ่มความท้าทายและพลิกแพลงได้มากยิ่งขึ้น โดยมีสิ่งที่เพิ่มขึ้นมาหลัก ๆ 4 อย่างคือ 1. ความซับซ้อนเพิ่มความเป็นเหตุและผลในคำถามและเพิ่มตัวเลือกจาก 4 เป็น 10 ตัวเลือกเพื่อลดการเดาสุ่มจากความน่าจะเป็น 2. ลดคำถามง่าย ๆ ทั่วไป ๆ ในชุด MMLU เดิมลง 3. เพิ่ม Prompt หลากหลายรูปแบบเพื่อให้สามารถวัดความสามารถของโมเดลได้แม้ว่า Prompt จะมีการเปลี่ยนแปลงไปบ้าง 4. เพิ่มประสิทธิภาพในการตอบอย่างมีเหตุผล และนอกจากนี้ก็มีเรื่องของขนาด Dataset และหัวข้อที่เกี่ยวข้องที่แตกต่างกันเล็กน้อย
- IFEval: เป็นชุดข้อมูลที่จะมี Instruction Prompt กำหนดมาให้และวัดผลว่าโมเดลทำตาม Prompt ที่สั่งได้มากน้อยแค่ไหน เช่น write an article with more than 800 words, wrap your response with double quotation marks. เป็นต้น
ด้านความเข้าใจในการเขียนภาษาโปรแกรมมิ่ง (Coding)
- HumanEval: ชุดข้อมูลสำหรับวัดประสิทธิภาพในการเขียนโค้ด Programming ต่าง ๆ ได้ถูกต้องมากน้อยแค่ไหน โดยมีทั้งหมด 164 ข้อตั้งแต่วัดความเข้าใจภาษา อัลกอริธึม และคณิตศาสตร์อย่างง่ายบางข้อเปรียบได้กับคำถามทั่วไปในการสัมภาษณ์งานด้านซอฟต์แวร์
- MBPP EvalPlus: ในชุดนี้จะวัดความสามารถในการเขียนโค้ดเช่นกัน แต่จะเป็นสำหรับภาษา Python โดยที่ครอบคลุมพื้นฐานไปจนถึงการใช้งานไลบรารี่ต่าง ๆ ในแต่ละข้อจะประกอบด้วยคำอธิบาย โค้ด และ Automate Test Cases 3 ข้อ
ด้านการคิดคำนวณคณิตศาสตร์
- GSM8K: ออกแบบมาเพื่อวัดผลความสามารถด้านคณิตศาสตร์ของโมเดล โดยจะเป็นโจทย์ปัญหาในระดับชั้นประถมศึกษาจำนวน 8,500 ข้อ ที่สร้างขึ้นโดยมนุษย์ แบ่งออกเป็น 7,500 ข้อสำหรับเทรนโมเดลและอีก 1,000 ข้อสำหรับทดสอบโมเดล สำหรับการแก้ปัญหาจะต้องใช้ประมาณ 2 ถึง 8 ขั้นตอนโดยทำบวก ลบ คูณ หาร ตามปกติไม่ซับซ้อนเกินไป
- MATH: ใช้วัดผลความสามารถด้านคณิตศาสตร์เช่นกัน มีทั้งหมด 12,500 ข้อ และมีความยากมากกว่า GSM8K
ด้านการคิดแบบเป็นเหตุและผล
- ARC Challenge: ชุดข้อมูลที่ออกแบบมาเพื่อวัดผลด้าน Reasoning ของโมเดล โดยเป็นคำถามแบบหลายตัวเลือก ส่วนใหญ่จะมี 4 ตัวเลือกมีแค่ไม่กี่ข้อที่มี 3 หรือ 5 ตัวเลือก และเป็นคำถามวิทยาศาสตร์ตั้งแต่ชั้นประถมจนมัธยมศึกษาตอนต้นไล่ตั้งแต่ง่าย ๆ ไปจนความยากที่ต้องใช้เหตุผลตอบ
- GPQA: Graduate-Level Google-Proof Q&A Benchmark หลัก ๆ ยังมีไว้เพื่อวัดผลด้าน Reasoning เหมือนเดิม โดยคำถามมีด้วยกัน 448 ข้อเป็นแบบหลายตัวเลือกภายในวิชาฟิสิกส์และเคมี แต่จะมีความยากในระดับที่สูงมาก (ระดับปริญญาเอก) ชุดข้อมูลแบบนี้จึงเรียกได้ว่าออกแบบมาเพื่อดูว่าขีดจำกัดของ LLM นั้นมีแค่ไหนและช่วยให้มนุษย์กับโมเดลทำงานร่วมกันได้มากน้อยเพียงใด
ด้านการเรียกใช้งานฟังก์ชันและเครื่องมือต่าง ๆ
- BFCL: Berkeley Function-Calling Leaderboard ตามชื่อ ข้อมูลชุดนี้สร้างขึ้นมาเพื่อวัดผลว่าโมเดลสามารถที่จะเรียกใช้ฟังก์ชันของเครื่องมือต่าง ๆ ได้ถูกต้องหรือไม่ ข้อมูลประกอบด้วยฟังก์ชันมากมายทั้งจาก Java, JavaScript, REST API, SQL, Python เป็นต้น
- Nexus: Nexus Function Calling Benchmark เป็นชุดข้อมูลที่สร้างขึ้นเพื่อทดสอบการเรียกใช้งานฟังก์ชันต่าง ๆ เช่นกัน โดยในชุดข้อมูลประกอบด้วยวิธีการเรียกใช้งาน API ที่มีการใช้กันในโลกจริง ๆ เช่น NVDLibrary, VirusTotal, OTX, Places API, and Climate API
ด้านความเข้าใจในข้อความที่มีบริบทยาวมาก ๆ
- ZeroSCROLLS/QuALITY: A Zero-Shot Benchmark for Long Text Understanding ข้อมูลชุดนี้ออกแบบมาเพื่อวัดผลความเข้าใจของโมเดลเมื่อเจอกับข้อความที่มีความยาวมาก ๆ โดยที่ไม่มีการฝึกสอนโมเดลเพิ่มเลย (Zero-shot)
- InfiniteBench/En.MC: ออกแบบมาเพื่อวัดความเข้าใจของโมเดลเมื่อเจอกับข้อความที่ยาวมาก ๆ เช่นกันครอบคลุม 12 หัวข้อเฉพาะทางและมีบริบทที่เป็นทั้งปัญหาในโลกจริงและปัญหาที่สังเคราะห์ขึ้น
- NIH/Multi-needle: Multi-Needle in a Haystack ยังคงออกแบบมาเพื่อวัดผลเมื่อเจอบริบทข้อความยาว ๆ เช่นกัน แต่จะเน้นไปที่การให้เหตุผลและหาข้อเท็จจริงจากข้อความจำนวนมาก ดั่งชื่อ (ถ้าแปลเป็นสำนวนไทยก็คือหาเข็มหลายเล่มในมหาสมุทร)
ด้านความเข้าใจในหลาย ๆ ภาษานอกจากภาษาอังกฤษ
- Multilingual MGSM: The Multilingual Grade School Math เช่นเดียวกับ GSM8K แต่แปลเป็นภาษาต่าง ๆ นอกจากภาษาอังกฤษ
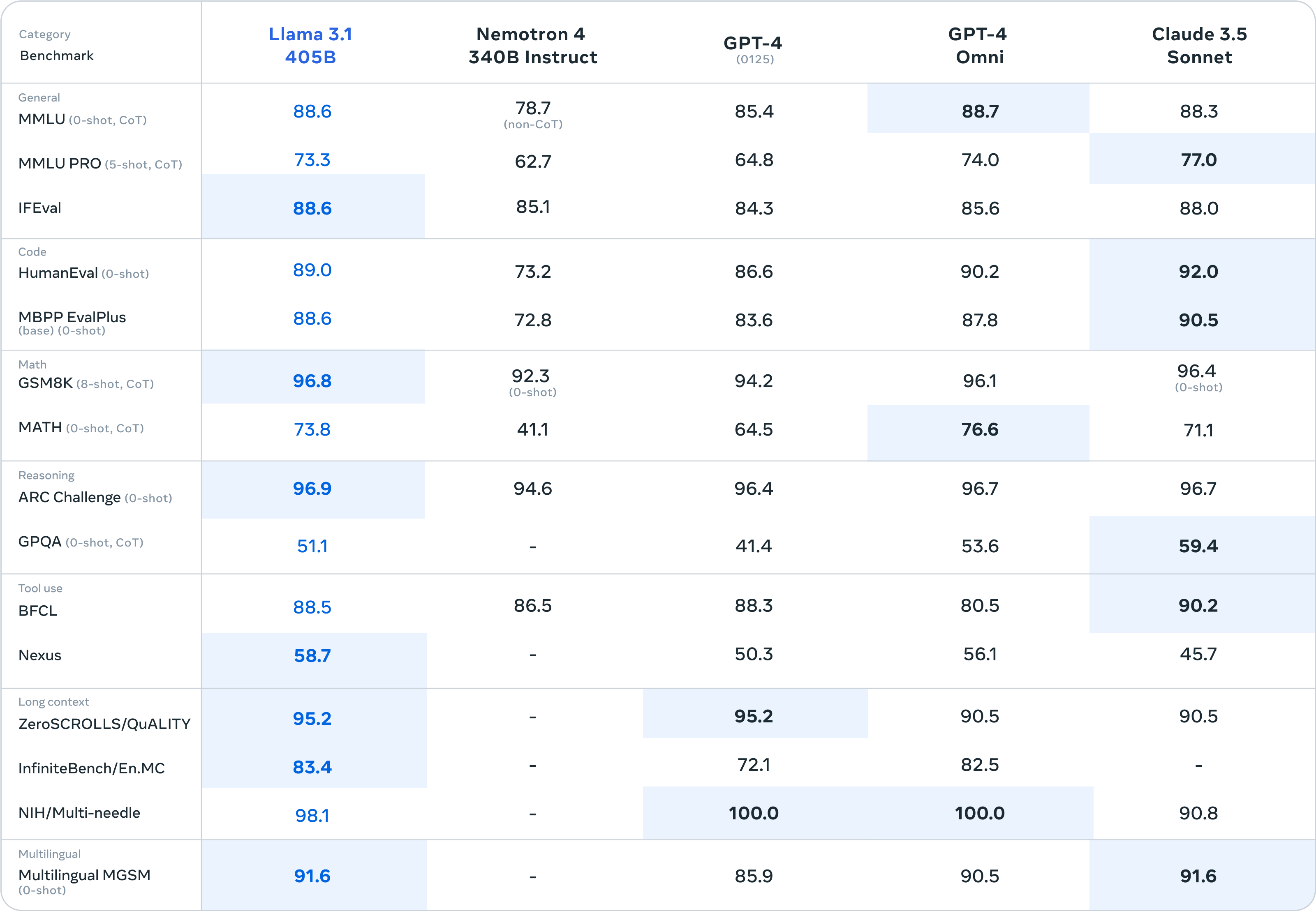
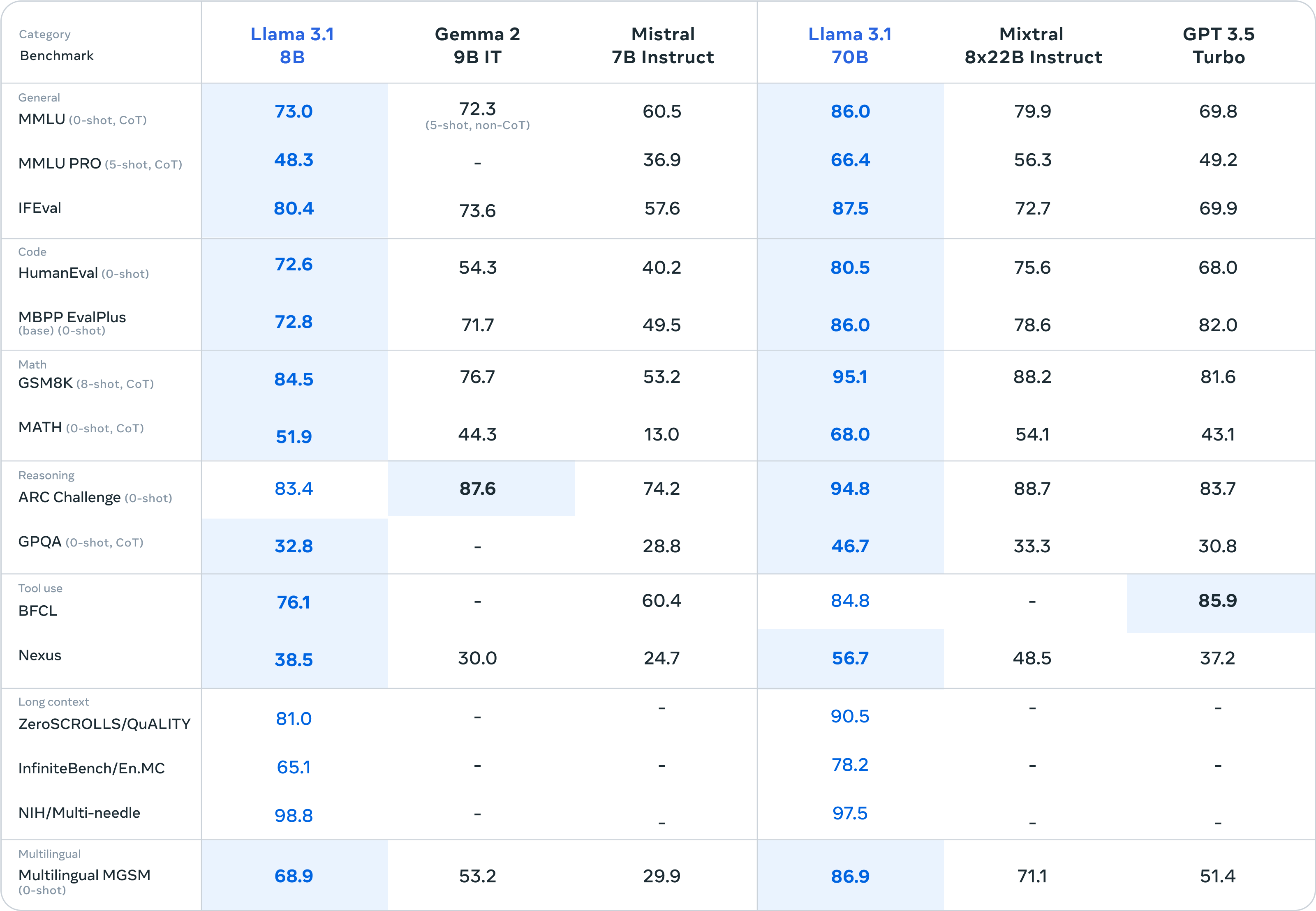
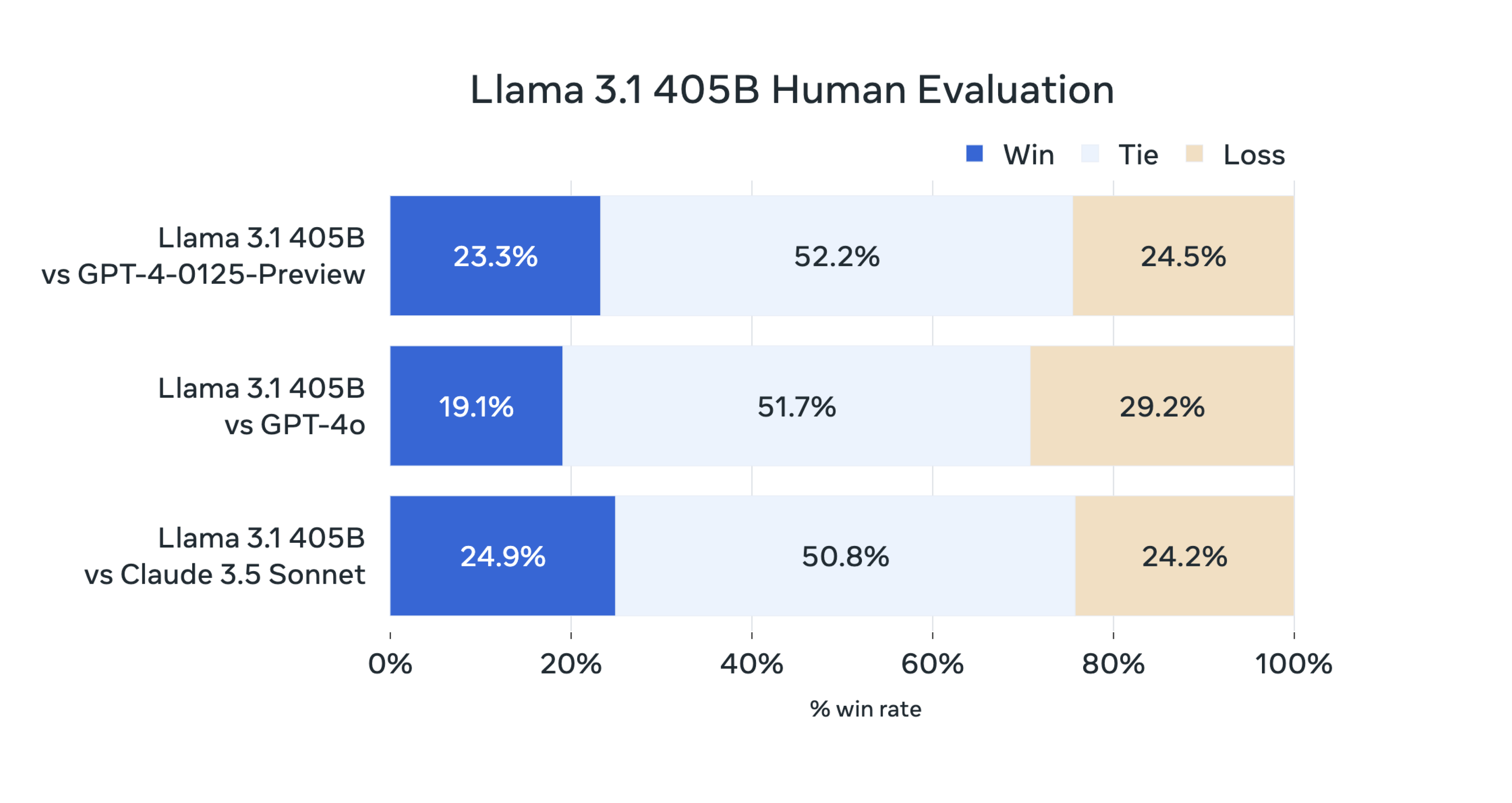
คะแนนที่ Llama 3.1 ทำได้นั้นเป็นไปดังตารางด้านล่างนี้
ทำความเข้าใจเพิ่มเติมกับ Llama Model Architecture
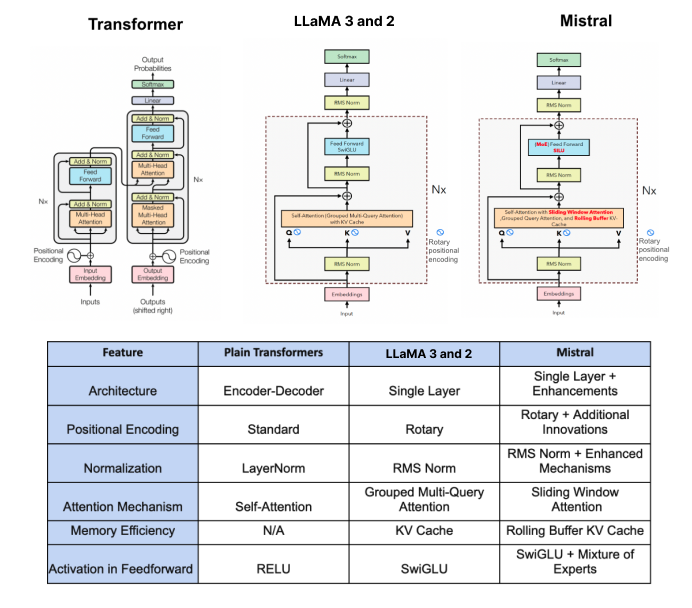
อย่างแรกมาดูกันที่ข้อแตกต่างของ Llama 3 และ Llama 2 กันก่อน จุดที่แตกต่างหลัก ๆ อย่างแรกคือ Tokenizer เปลี่ยนจาก SentencePiece เป็น Tiktoken (Tokenizer เข้าใจง่าย ๆ ว่าเป็นวิธีการที่จะแสดงถึงคำศัพท์ต่าง ๆ ในรูปแบบของตัวเลข ดังนั้น Tokenizer แต่ละตัวจึงต่างกันที่ว่ามองคำศัพท์หนึ่งคำอย่างไร) จำนวนข้อมูลที่ใช้ฝึกสอนจาก 2.2 พันล้านโทเค็น เป็น 1 หมื่น 5 พันล้านโทเค็น (Tokens คือค่า 1 ค่าที่แสดงถึงคำศัพท์ 1 คำใน Tokenizer) ความยาวของบริบทที่รองรับเพิ่มจาก 4096 โทเค็นเป็น 8192 โทเค็น และสุดท้ายเพิ่มภาษาที่รองรับจาก 20 ภาษาเป็น 30 ภาษา (มีภาษาไทยด้วย) (ส่วนใน 3.1 หลัก ๆ คือเพิ่มขีดความสามารถให้ดีขึ้น)
ถัดมาเราจะมาทำความเข้าใจเกี่ยวกับโมเดล Llama 3 ว่ามีรายละเอียดอย่างไรบ้าง โมเดล Llama 3 นั้นใช้ RMSNorm (Root Mean Squared) เป็นแนวทางในการ Normalized แต่ละ Input ใน Transformers (เช่นเดียวกันกับตอนยังเป็น Llama 2) โดยที่หน้าที่หลักของ RMSNorm คือการให้ความสำคัญกับข้อมูลส่วนที่มีความสำคัญที่สุดต่อการเรียนรู้ก่อน แทนที่จะสนใจและใช้เวลาเรียนรู้ในทุก ๆ อย่างเท่ากันไปทั้งหมด (เช่นเดียวกับ chatGPT ด้วย) ดังนั้น Input ที่ส่งเข้าไปเทรนโมเดลจะมี Weights ที่กำหนดไว้ว่าฟีเจอร์ไหนที่ต้องให้ความสำคัญก่อนจะมี Weights ที่เยอะกว่า และฟีเจอร์ที่สำคัญน้อยจะมี Weights ที่น้อยกว่า (ถ้าในมุมของ LLM ก็คือจะพยายามทำความเข้าใจข้อความที่สำคัญ ๆ ในบริบทของข้อความที่เราให้ไปก่อน)
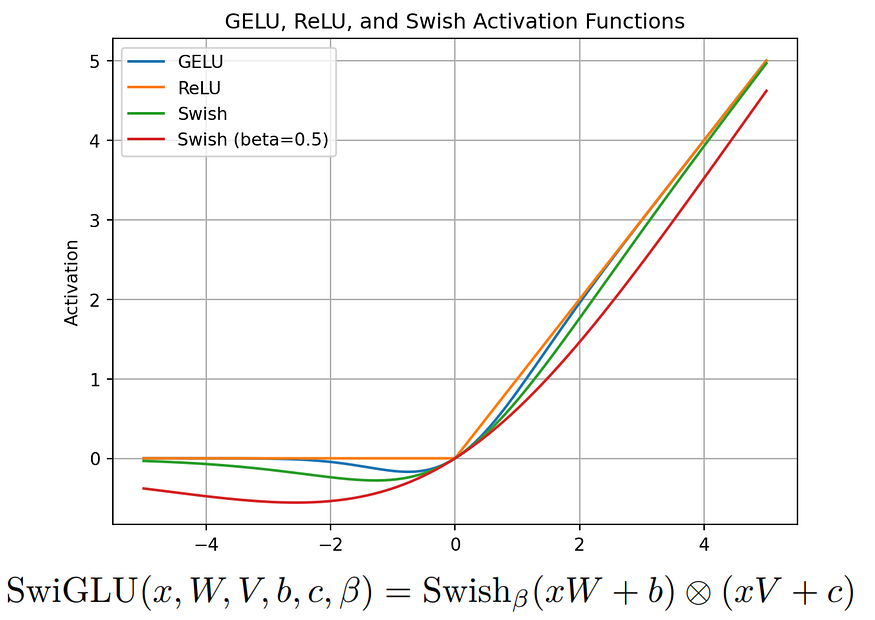
ในส่วนของ Activation Function โมเดล Llama จะใช้เป็น SwiGLU ดังกราฟที่เห็นด้านล่างนี้เส้นสีเขียวกับเส้นสีแดงจะเห็นว่าเส้นมีความโค้งที่มากกว่า เส้นสีฟ้าและส้ม (GELU, ReLU) โดยความโค้งมากขึ้นตามค่า Beta ซึ่งการที่เส้นมีความโค้งมากขึ้นนี้จะทำให้สามารถปรับเข้ากับปัญหาได้หลากหลายและเหมาะสมมากยิ่งขึ้น (เพราะงานของ LLM นั้นไม่ได้ออกแบบเพื่อจำแนกข้อมูลอย่างชัดเจนเหมือนพวก Classification แบบต่าง ๆ ที่เหมาะกับ ReLU มากกว่า) หน้าที่หลักของ SwiGLU คือช่วยปรับเรื่องการให้ความสำคัญกับคำหรือวลีตามความสัมพันธ์กับบริบทของข้อความนั้น ๆ (จินตนาการว่าเหมือนไฮไลท์ส่วนที่สำคัญ ๆ ในหนังสือก็ได้)
Rotary Embeddings (RoPE) เป็น Positional Embeddings ที่ใช้ในโมเดล Llama 3 ซึ่งตามปกตินั้นในข้อความยาว ๆ อันหนึ่งเราจะประกอบขึ้นมาจากคำหนึ่งคำมารวมกันเป็นวลีเป็นประโยค โดยที่คำหนึ่งคำนี้เราจะเรียกว่าโทเค็น (Token) ซึ่งโทเค็นแต่ละอันจำเป็นจะต้องมีลำดับกำหนดไว้เพื่อให้รู้ว่ามันอยู่ตรงไหนในทั้งประโยคหรือบริบทนั้น ๆ ซึ่งเป็นหน้าที่ของ Positional Embeddings และความพิเศษของ RoPE อยู่ตรงที่มันสามารถที่จะสับเปลี่ยนตำแหน่งของโทเค็นได้โดยที่ยังคำนึงถึงความสัมพันธ์กับคำหรือบริบทรอบ ๆ ของตัวมันเองด้วย วิธีนี้จะช่วยให้โมเดลสามารถทำความเข้าใจคำแต่ละคำได้หลากหลายกว่ารู้ว่าคำ ๆ นี้อ้างอิงถึงประโยคหรือคำไหนมาก่อนหรือไม่แทนที่จะสนใจแค่คำก่อนหน้าหรือคำถัดไปใกล้ ๆ เพียงอย่างเดียว
Llama 3 ใช้ Byte Pair Encoding ในการทำ Tokenizer (แปลงจากข้อความเป็นค่าตัวเลขค่าหนึ่ง) โดยที่ BPE มีหลักการทำงานเบื้องต้นดังนี้ สมมุติว่าเรามีคลังคำศัพท์อยู่หนึ่งชุดได้แก่
(“มะละกอส้ม”, “ส้มกล้วย”, “ส้มมะละกอ”, “มะละกอกล้วยส้ม”, “กล้วยมะละกอส้ม”, “ส้มกล้วยมะละกอ”) และกำหนดให้ชุดคำศัพท์เริ่มต้นเป็นแต่ละคำในคลังคำศัพท์จะได้เป็น {มะละกอ, ส้ม, กล้วย} และแทนค่าด้วยความถี่ของคำศัพท์เหล่านี้ด้วยความถี่ที่ปรากฎในคลังคำศัพท์จะได้เป็น {มะละกอ: 5, ส้ม: 6, กล้วย: 4} ซึ่งการออกแบบคำศัพท์ใน Tokenizer นั้นจะมีการกำหนดขนาดสูงสุดที่เราต้องการไว้หรือจนกว่าจะครบทุกรูปแบบคำที่เป็นไปได้ ในที่นี้จะใช้วิธีการนับรูปแบบของคำที่มีและเพิ่มเข้าไปเรื่อย ๆ เช่น
- คำว่า กล้วยส้ม ปรากฎ 1 ครั้งจะเป็น {มะละกอ: 5, ส้ม: 5, กล้วย: 3, กล้วยส้ม: 1}
- คำว่า มะละกอส้ม ปรากฎ 2 ครั้งเป็น {มะละกอ: 4, ส้ม: 4, กล้วย: 3, กล้วยส้ม: 1, มะละกอส้ม: 2}
- คำว่า กล้วยมะละกอ ปรากฎ 2 ครั้งเป็น {มะละกอ: 3, ส้ม: 4, กล้วย: 2, กล้วยส้ม: 1, มะละกอส้ม: 2, กล้วยมะละกอ: 2}
- คำว่า ส้มกล้วย ปรากฎ 2 ครั้ง เป็น {มะละกอ: 3, ส้ม: 3, กล้วย: 1, กล้วยส้ม: 1, มะละกอส้ม: 2, กล้วยมะละกอ: 2, ส้มกล้วย: 2}
- คำว่า มะละกอกล้วยส้ม ปรากฎ 1 ครั้ง เป็น {มะละกอ: 3, ส้ม: 3, กล้วย: 1, กล้วยส้ม: 0, มะละกอส้ม: 2, กล้วยมะละกอ: 2, ส้มกล้วย: 2, มะละกอกล้วยส้ม: 1}
- คำว่า กล้วยมะละกอส้ม ปรากฎ 1 ครั้ง เป็น {มะละกอ: 3, ส้ม: 3, กล้วย: 1, กล้วยส้ม: 0, มะละกอส้ม: 1, กล้วยมะละกอ: 1, ส้มกล้วย: 2, มะละกอกล้วยส้ม: 1, กล้วยมะละกอส้ม: 1}
- คำว่า ส้มกล้วยมะละกอ ปรากฎ 1 ครั้ง เป็น {มะละกอ: 3, ส้ม: 3, กล้วย: 1, กล้วยส้ม: 0, มะละกอส้ม: 1, กล้วยมะละกอ: 0, ส้มกล้วย: 1, มะละกอกล้วยส้ม: 1, กล้วยมะละกอส้ม: 1, ส้มกล้วยมะละกอ: 1}
ตัว Byte Pair Encoding จะทำแบบนี้ไปเรื่อยจนครบทุกคู่ของคำที่มีในคลังคำศัพท์ของเรา ซึ่งจะทำให้ครอบคลุมจำนวนคำศัพท์ได้มากขึ้นแม้ว่าจะเป็นคำทั่ว ๆ ไปหรือคำที่ปรากฏไม่บ่อยก็ตาม จุดเด่นสำคัญคือมันจะเก็บคำทั้งคำยาว ๆ อย่าง มะละกอกล้วยส้ม ไว้ด้วย แทนที่จะนับแยกเป็น มะละกอ กล้วย ส้ม เพียงอย่างเดียว (ซึ่งเป็นสิ่งที่ Sentence Piece ทำ)
Conclusion
โดยรวมแล้ว LLaMA 3.1 ถือเป็น LLM ตัวใหม่ที่เปิดให้ใช้ได้แบบฟรี Opensource ที่มีคุณภาพและความสามารถทัดเทียมหรือเหนือกว่าโมเดลในท้องตลาด และโครงสร้างหลัก ๆ นั้นคือ Transformer ส่วน Decoder และมีลักษณะของ Tokenization, Normalized Layer, Activation Function ที่แตกต่างออกไปรวมถึงข้อมูลกับวิธีการฝึกสอนด้วย ทั้งนี้หากอยากลองใช้งานสามารถศึกษาเพิ่มเติมได้ที่ https://www.llama.com/
ขอขอบคุณข้อมูลจาก
https://ai.meta.com/blog/meta-llama-3-1/
https://lightning.ai/fareedhassankhan12/studios/building-llama-3-from-scratch
https://iwooky.substack.com/p/ai-benchmarking-with-llama-31


