Llama 3.1 สำหรับงาน
Text Classification
Llama 3.1 โมเดล LLM แบบ Generative AI ที่มีความสามารถในการสร้างข้อความตอบคำถามแนะนำโต้ตอบได้จาก Meta (อ่านเพิ่มเติมได้ที่นี่) แต่หากพูดในเชิงโครงสร้างแล้ว Llama เองก็ใช้แต่ส่วน Decoder ของ Transformer เป็นหลักเช่นเดียวกันกับตระกูล GPT และ LLM ที่เน้นการสร้างข้อความตัวอื่น ๆ ด้วย ฉะนั้นแล้วจะบอกว่าโมเดลจำพวกนี้เน้นไปที่การสร้างข้อความให้ถูกต้องเหมาะสมที่สุดกับสิ่งที่มันเห็นหรือถูกถามก็ว่าได้ แต่จริง ๆ แล้วไม่ได้เข้าใจบริบทหรือความหมายของข้อความนั้นเลย เปรียบเสมือนกับการที่คนเราอ่านหนังสือมาเยอะมากแล้วจำมาพูดต่อได้เป็นอย่างดีปรับเปลี่ยนคำให้กระชับได้ แต่หากให้แก้ไขหลักการทำงานของเรื่องดังกล่าวหรือปรับเปลี่ยนให้เหมาะกับงานเฉพาะอย่างมากขึ้นก็จะไม่สามารถทำได้ทันที
ดังนั้นแล้วการที่จะให้โมเดล LLM สามารถทำงานเฉพาะอย่างได้ดีเราจำเป็นจะต้องเสริมจุดแข็งของโมเดลให้ดีมากยิ่งขึ้นหรือก็คือเสริมความสามารถในการทำ Next Sentence Prediction ของมันให้ดียิ่งขึ้นด้วยการให้โมเดลดูตัวอย่างของข้อมูลที่ควรจะเป็นและฝึกคาดเดาคำที่จะต้องเติมให้ถูกต้องมากขึ้นเรื่อย ๆ จนมันสามารถที่จะจำรูปแบบของข้อความที่รับเข้ามาและข้อความที่มันควรจะสร้างออกไปได้
แม้จะเป็นงานอย่าง Text Classification ที่ปกติแล้วมักจะใช้โมเดลจำพวก Encoder ในการทำก็ตาม LLM เองก็สามารถทำได้เช่นกัน เพราะถึงแม้มันจะไม่เข้าใจบริบทซะทีเดียวแต่มันก็จดจำรูปแบบได้อย่างชัดเจนมากพอที่จะเดาคำตอบได้ แต่หากเป็นงานจริง ๆ ผู้เขียนแนะนำว่าถ้าจะทำด้าน Text Classification ยังไงซะใช้โมเดลจำพวก Encoder หรือทำ Embeddings อื่น ๆ แล้วใช้ Classifier มาทำนายจะยังคงดีกว่าในแง่ของทรัพยากรการประมวลผลที่ต้องใช้และเวลาด้วย แต่ในบทความมีวัตถุประสงค์ที่ต้องการแสดงให้เห็นว่า Llama 3.1 ก็สามารถทำงาน Classification ได้เช่นกันและเราอาจจะนำความสามารถนี้ไปสร้างชุดข้อมูลจำลองเพื่อไปสอนโมเดลตัวเล็กอื่น ๆ ให้ดีขึ้นก็อาจเป็นไปได้
ชุดข้อมูลที่ใช้ในตัวอย่างนี้
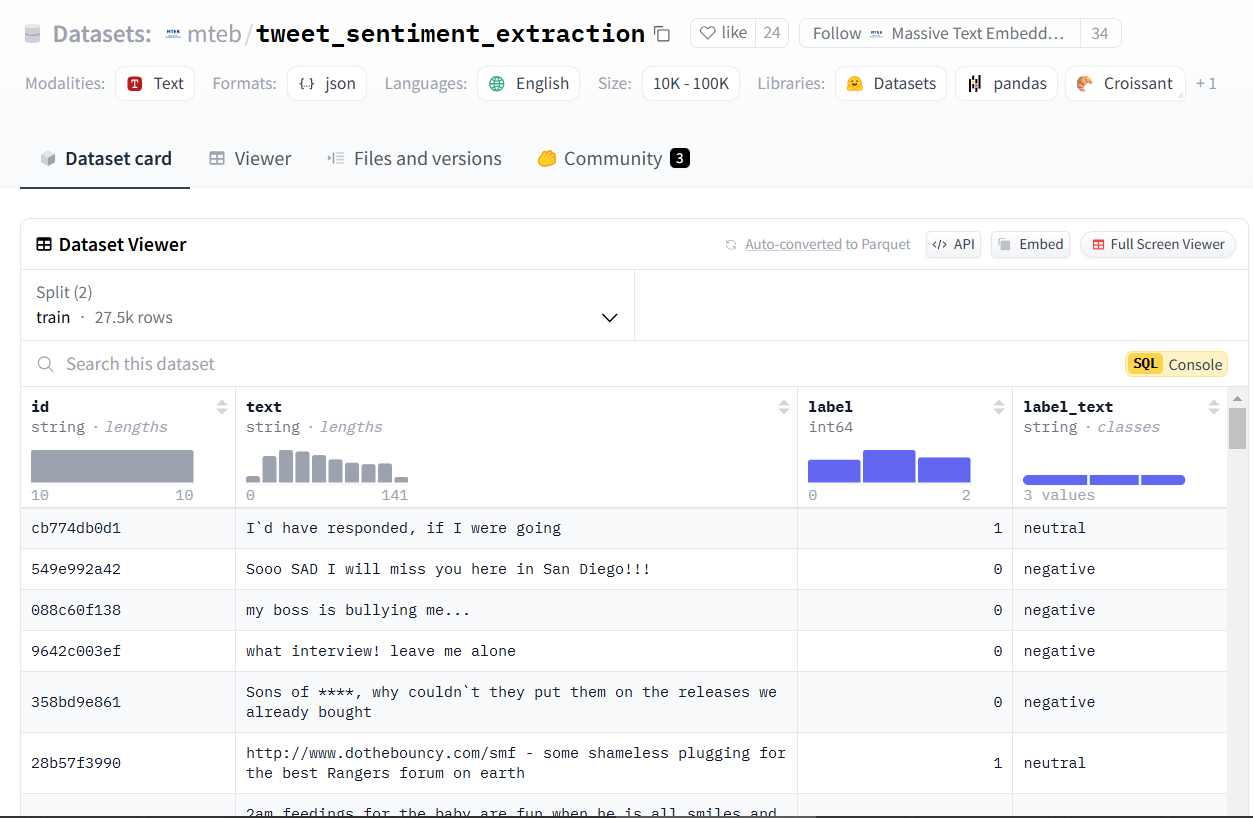
ข้อมูลจาก Hugging Face ชุด mteb/tweet_sentiment_extraction โดยเกี่ยวข้องกับ Sentiment ของข้อความที่ถูกทวีตในทวิตเตอร์ (สมัยยังเป็นทวิตเตอร์) จะประกอบด้วยความรู้สึกเชิงบวก (Positive), ความรู้สึกเชิงลบ (Negative), และความรู้สึกเป็นกลาง (Neutral)
ข้อมูลทั้งหมดจะมีประมาณ 31,015 rows แบ่งเป็น Train ประมาณ 27,481 และ Test 3,534 แต่เราจะเลือกมาทั้งหมดเพียงแค่ Train จำนวน 3,200 Validation จำนวน 800 และ Test จำนวน 300 เท่านั้นเพื่อความรวดเร็ว
1. เตรียมชุดข้อมูลสำหรับ Train และ Test

ในการเตรียมข้อมูลสำหรับ Fine-tuning LLM นั้นจะเตรียมในลักษณะของ Prompt ที่มีโครงสร้างชัดเจนพร้อมกับบอกชนิดงานและคำตอบที่เราต้องการให้มันทำ ยกตัวอย่างเช่นในงานนี้เราจะมี Prompt 2 แบบดังนี้
- Prompt สำหรับ Train และ Validation จะใช้โครงสร้างแบบเดียวกันให้โมเดลได้เรียนรู้และวัดผลจาก Loss Function ที่ลดลง ลักษณะเช่น
Classify the text into negative, neutral, positive, and return the answer as the corresponding tweet text sentiment label.
text: ข้อความจากทวิต
label: ความรู้สึกต่อทวิตนั้น (neutral or negative or positive อันใดอันหนึ่ง) - Prompt สำหรับ Test จะเว้นว่างส่วนของ Label ไว้เพื่อให้โมเดลได้ลองตอบด้วยตัวเองและวัดผลด้วย Metrics สำหรับงาน Classification ตามปกติ เช่น
Classify the text into negative, neutral, positive, and return the answer as the corresponding tweet text sentiment label.
text: ข้อความจากทวิต
label: (เว้นว่างไว้ได้เลย)
ทั้งสองส่วนนี้เขียนเป็นฟังก์ชันและนำไปเตรียมเป็นชุดข้อมูลให้เรียบร้อย
2. โหลด Model & Tokenizer ของ Llama 3.1 8B พร้อมปรับ Config ให้ใช้งานได้บน Colab Free (T4 GPU)
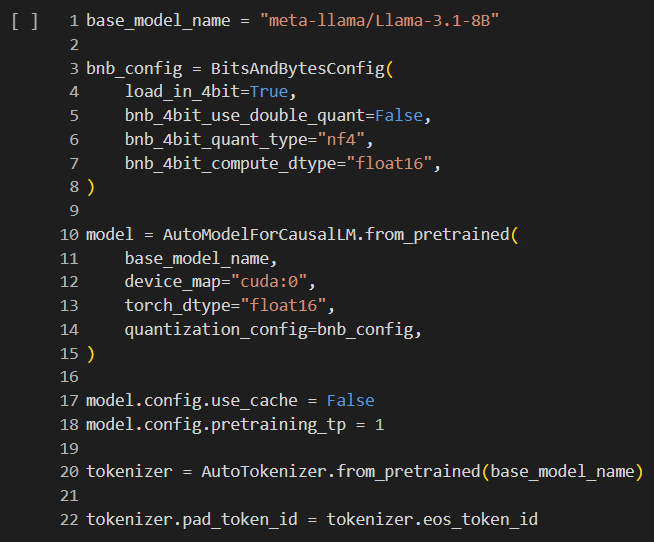

- กำหนด Config ของ BitAndBytes เพื่อให้สามารถทำ Quantization กับตัวโมเดล Llama 3.1 ได้ สิ่งนี้จะช่วยให้ประหยัด Memory ที่โมเดลจะต้องใช้ไปได้มาก แต่ก็แน่นอนว่าคุณภาพในตอนที่ฝึกสอนโมเดลก็ลดลงเล็กน้อยเช่นกัน
- โหลดตัวโมเดลจาก meta-llama/Llama-3.1-8B ปโดยกำหนด torch_dtype เป็น float16 และใส่ Quatization Config ตามที่กำหนดในข้อ 1 เพื่อให้ประหยัด Memory (config.pretraining_tp เท่ากับ 1 นั้นจะช่วยให้โมเดลทำงานเร็วขึ้น แต่ความถูกต้องอาจลดลงเล็กน้อย หากมี Memory และเวลาเหลือเฟือลองตั้งค่าเป็นเลขอื่นได้จะทำงานได้ถูกต้องตามประสิทธิภาพสูงสุดมากกว่า)
- โหลด Tokenizer และตั้ง Padding Token ID เป็น End of Sentence Token ID เพราะ Llama ไม่ได้ใช้ EOS Tokens
- แพ็คทุกอย่างรวมเข้าไปใน Pipeline และตั้งค่า Pipeline ให้ทำงาน Text Generation โดยที่ max_new_tokens หมายถึงจำนวน tokens ใหม่ที่จะให้โมเดลสร้าง และ temperature หมายถึงความสร้างสรรค์ต่อรูปแบบที่มันจะต้อง Generate ข้อความ ปกติจะอยู่ระหว่าง 0 ถึง 1 ยิ่งค่าน้อยจะหมายถึงให้มันสร้างภายใต้โครงสร้างและรูปแบบเดิม และยิ่งค่าสูงจะหมายถึงให้มันคิดรูปแบบใหม่ ๆ ที่ต่างจากเดิม ซึ่งในที่นี้เราอยากได้รูปแบบเดิมแต่แตกต่างแค่ Sentiment ที่มันตอบจึงตั้งให้น้อย ๆ ไว้
3. เตรียม Prediction Function และ Evaluate Function


- ส่วนของ Prediction Function นั้นหลัก ๆ จะโยนข้อความเข้าไปและให้โมเดลเติมข้อความที่เว้นว่างไว้ จากนั้นก็ Postprocessing เล็กน้อยเพื่อให้ได้ Label (Sentiment) ที่โมเดลตอบจริง ๆ
- Evaluation Function ในส่วนนี้ไม่มีอะไรต่างกับงาน Classification ทั่วไปสามารถใช้ Accuracy, F1, Classification Report เทียบระหว่างเฉลยและค่าทำนายได้ตามปกติ
4. ทดสอบ Predict และวัดผลโมเดลก่อนทำ Fine-tuning
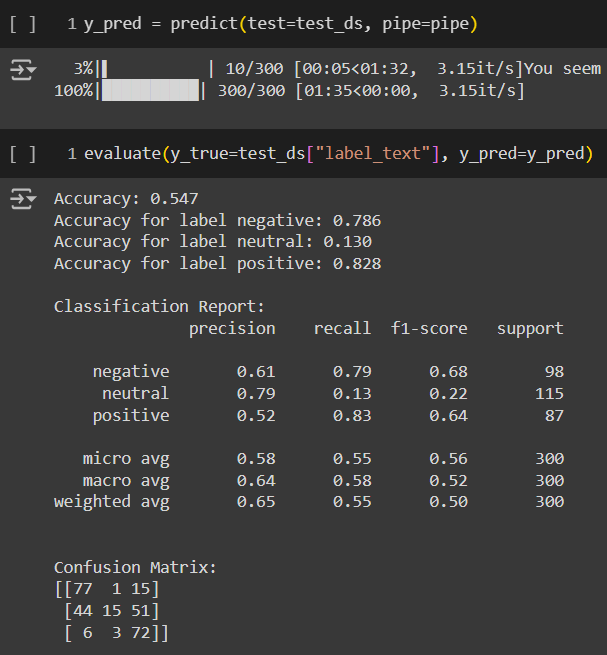
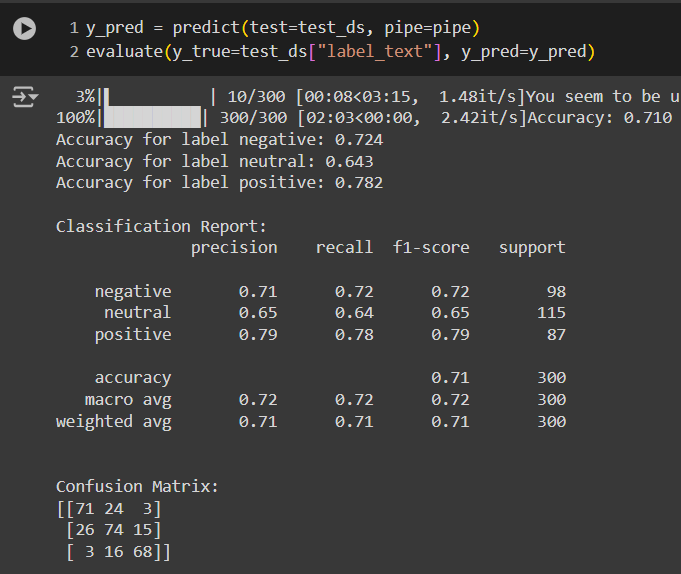
เรียกใช้งานฟังก์ชัน Prediction Function และโยนผลลัพธ์ที่ได้กับเฉลยเข้าไปใน Evaluation Function เพื่อดูประสิทธิภาพของโมเดลก่อน Fine-tune โดยมีผลดังรูปข้างต้นนี้
5. เตรียม Training Config สำหรับ Fine-tuning
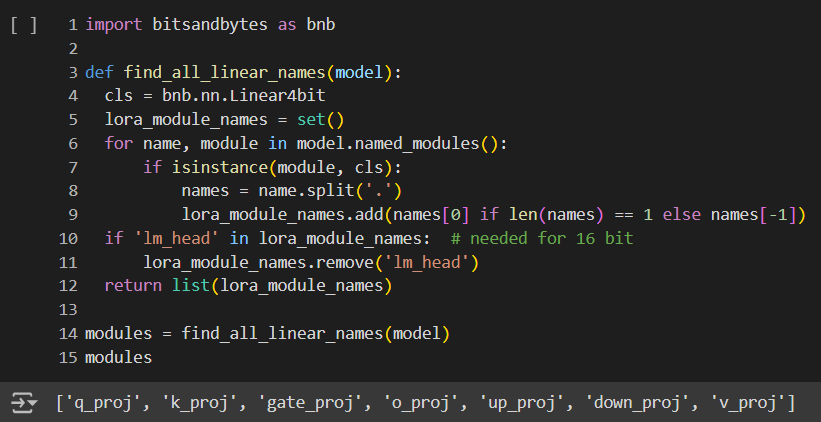


- หา Layers ทั้งหมดที่เราต้องการจะทำ Fine-tuning ด้วย เพื่อที่จะกำหนดใน LoRA ได้ว่ามันจะต้องปรับเลเยอร์ไหนและฟรีซเลเยอร์ไหนไว้บ้าง
- กำหนด LoRA Config อ่านเพิ่มเติมที่นี่
- กำหนด Training Arguments แนะนำให้ใช้ตามตัวอย่างด้านล่าง สำหรับรายละเอียดไว้จะมีอธิบายเพิ่มเติมในบทความถัด ๆ ไป
- แพ็คทุกอย่างเข้าในไปใน SFTTrainer (Supervised Fine Tuning) สำคัญคือกำหนดชื่อคอลัมน์ของ Prompt ในชุดข้อมูลของเราให้ตรง
6. Training & Evaluation
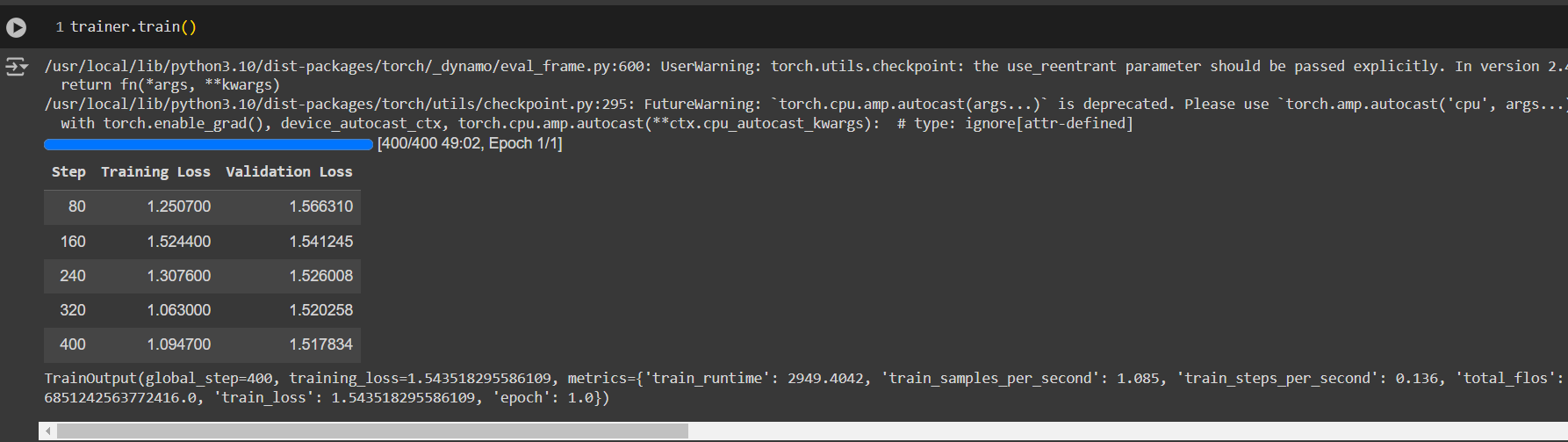


- เรียกใช้งาน trainer.train() เพื่อเริ่มต้นการฝึกสอนโมเดล โดยมันจะเซฟโมเดลไว้ให้ทุก ๆ Steps หรือ Epoch ที่กำหนด
- ระบบจะคอยรายงาน Loss ทุก ๆ ครั้งที่มันทำ Validation ที่เรากำหนด
- เมื่อเสร็จสิ้นเราสามารถโหลดโมเดล Llama 3.1 ที่เป็นตัว Pretrained มาอีกครั้งและ Merge รวมกับตัว Adapter (LoRA Weights) ที่เราได้ Fine-tuning ไปเมื่อครู่ได้
- จากนั้นลองทำ Prediction และ Evaluation อีกครั้งเพื่อวัดผลได้ โดยจะเห็นว่าผลลัพธ์ดีขึ้นเป็นอย่างมากสำหรับงาน Sentiment Classification นี้
Conclusion
Colab Notebook สามารถดูได้ที่นี่
จะเห็นว่าเมื่อ Fine Tune แล้วโมเดลมีประสิทธิภาพเพิ่มขึ้นมากอย่างเห็นได้ชัดสำหรับงาน Classification และด้วยวิธีนี้เราจะสามารถสร้าง Adapter หลาย ๆ ตัวมาผนวกหรือเลือกใช้กับ Llama 3.1 ตัวพื้นฐานได้ โดยไม่กระทบกับข้อมูลเดิมซึ่งอาจก่อให้เกิดปัญหา Catastrophic Forgetting ได้


