
SEER – FACEBOOK
Facebook ได้วิจัยและพัฒนาปัญญาประดิษฐ์ด้าน Computer Vision ตัวใหม่ที่ชื่อ SEER โดย AI นี้สามารถเรียนรู้รูปภาพด้วยตนเองนับพันล้านพารามิเตอร์

Video Conferencing with AI
NVIDIA พัฒนา AI เข้ามาช่วยให้ Video Conferencing มีประสิทธิภาพมากยิ่งขึ้นแม้ในสภาพที่สัญญาณอินเตอร์เนตมีความล่าช้าก็ตาม

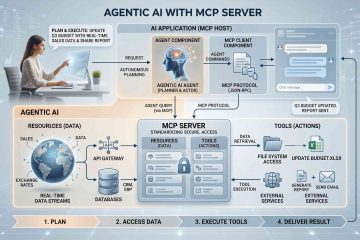
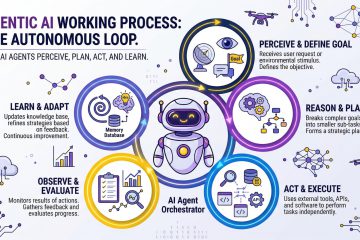
What is Agentic AI – AI
Agentic AI คือ ระบบที่นำ LLM มาเชื่อมต่อเข้ากับระบบต่าง ๆ เพื่อสร้างเป็นระบบอัตโนมัติที่สามารถคิดและตัดสินใจทำเรื่องต่าง ๆ แทนมนุษย์ได้