





Food – AI & Life
ของเหลือในตู้เย็นมักถูกทิ้งหรือเก็บไว้จนเสียทิ้งหรือไม่รู้จะนำไป ทำเมนูอะไรดี Hellmann จึงนำเสนอ AI ที่จะช่วยคิดสูตรอาหารจากของเหลือที่มี
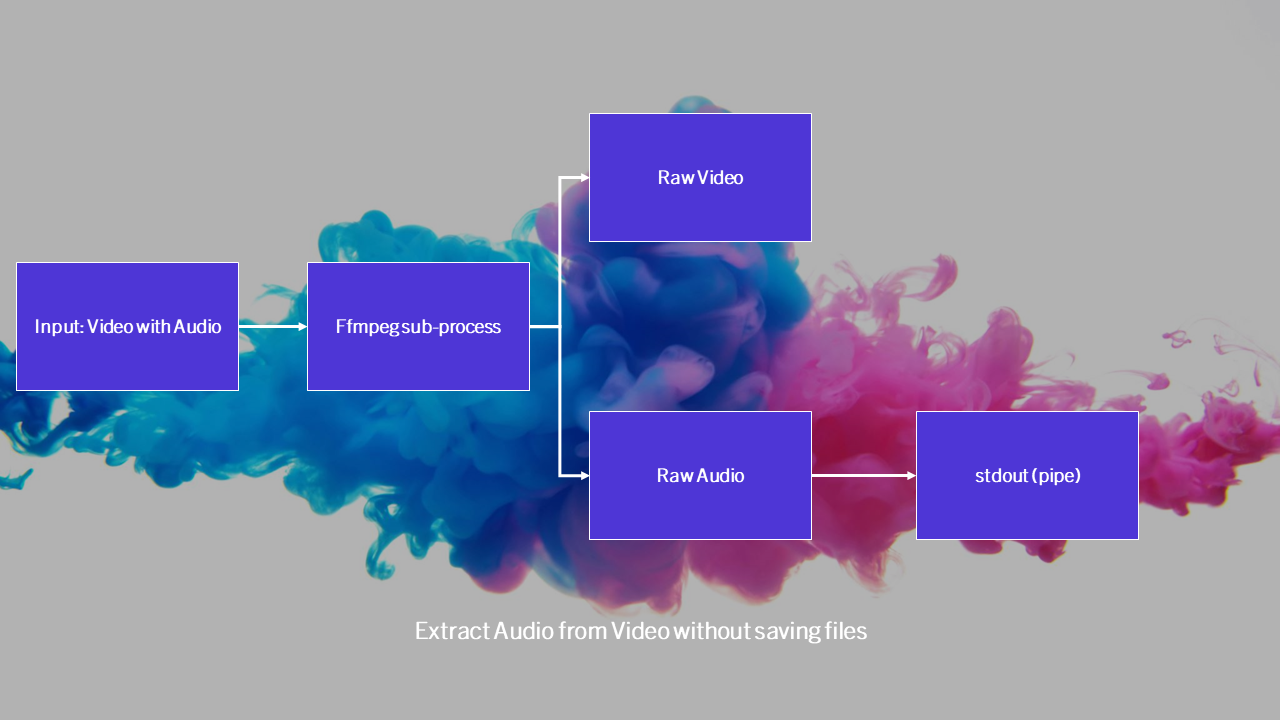
Extract Audio from Video – Data
วิธีการดึงเสียงออกจากวิดีโอด้วย Python โดยประมวลผลแบบ In-Memory ไม่ต้องบันทึกไฟล์ลงเครื่องเพื่อความสะดวกในการใช้งานกับระบบ
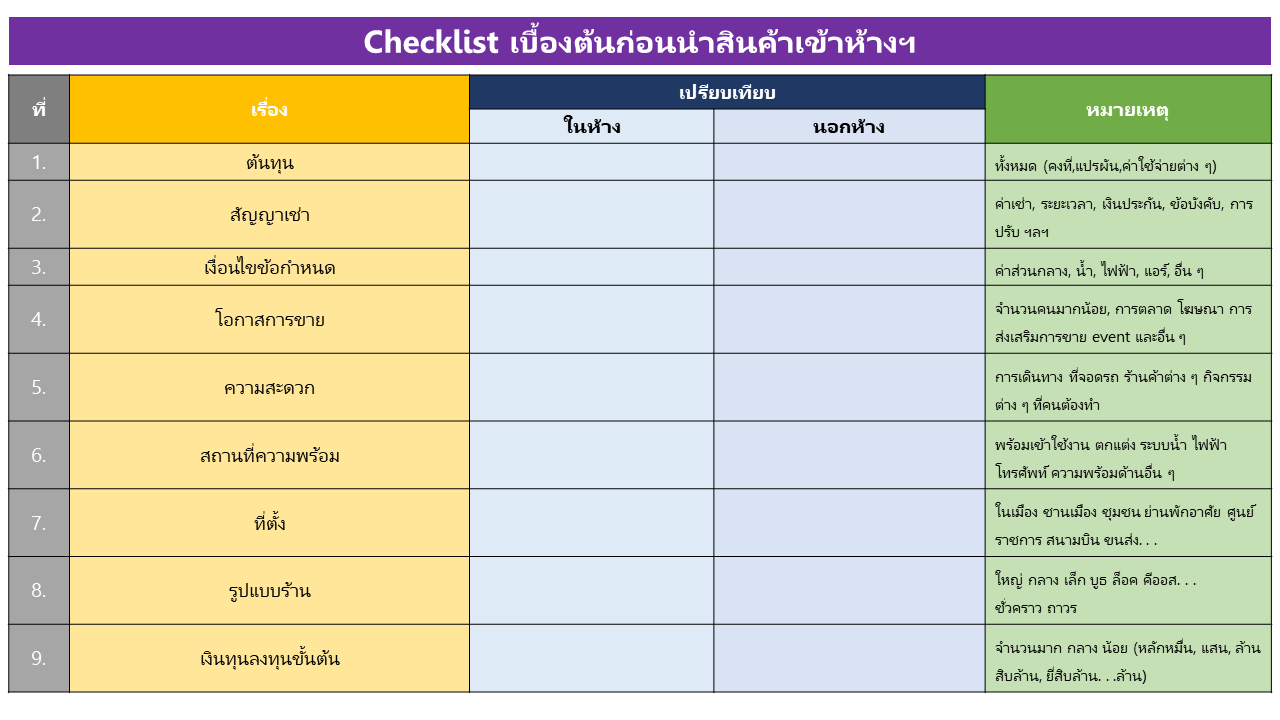
Modern Trade Check List – SBC
จะขายในห้าง (Modern Trade) หรือนอกห้าง แบบไหนจะดีกว่ากัน? สิ่งที่ต้องเช็คและเปรียบเทียบใน การนำสินค้าเข้าห้าง



