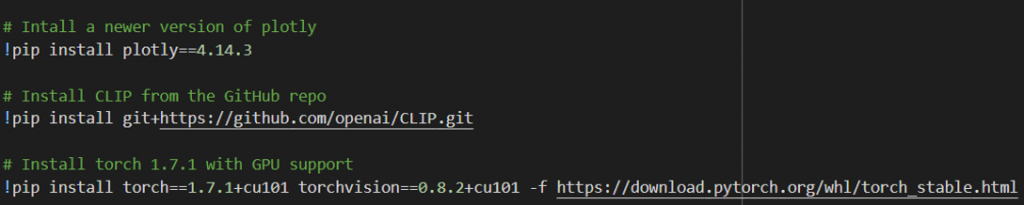
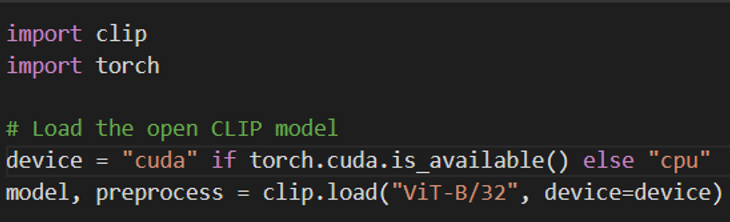
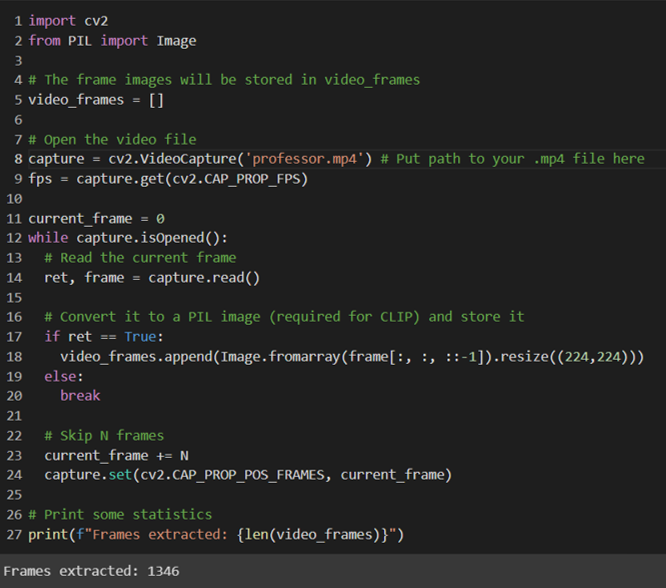
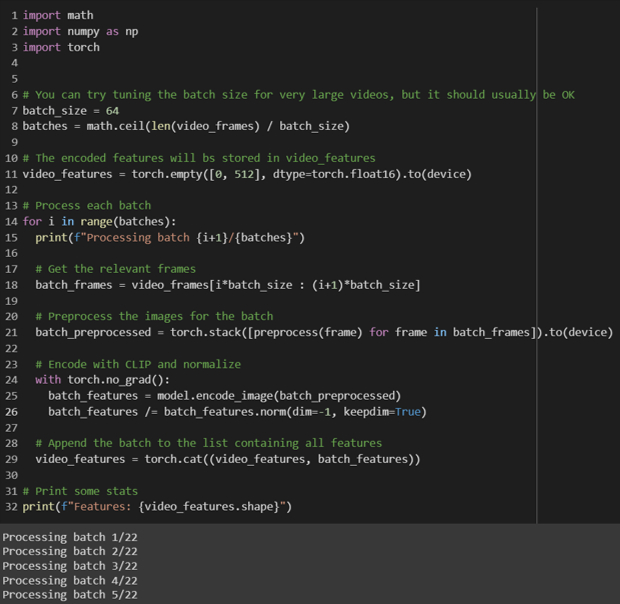
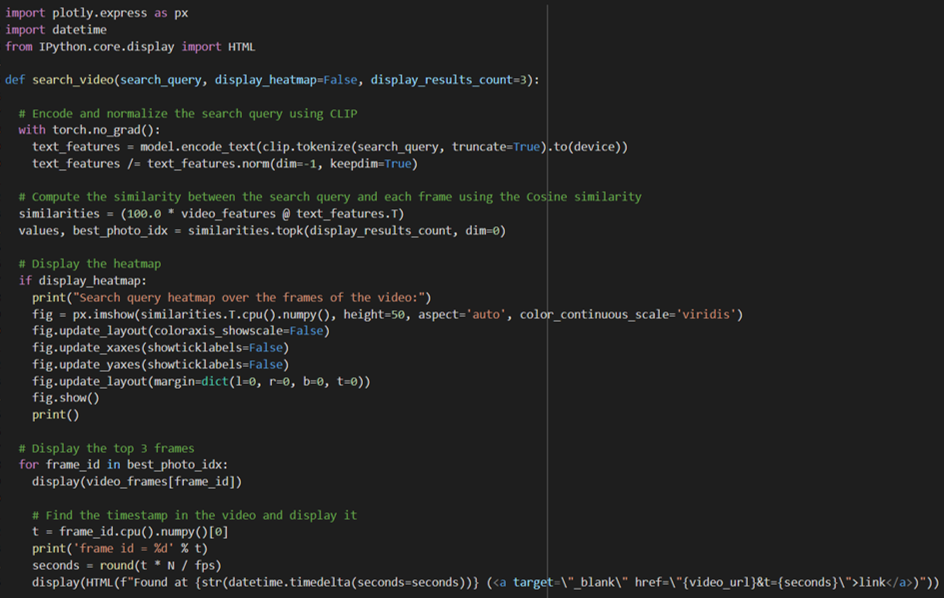
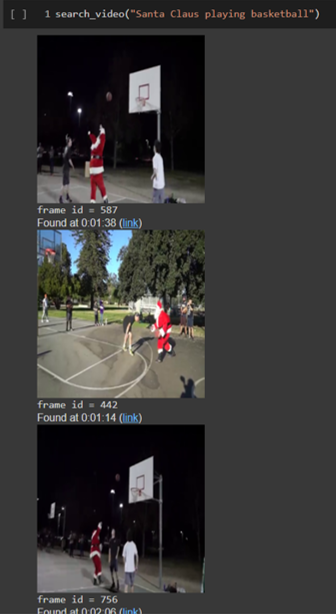
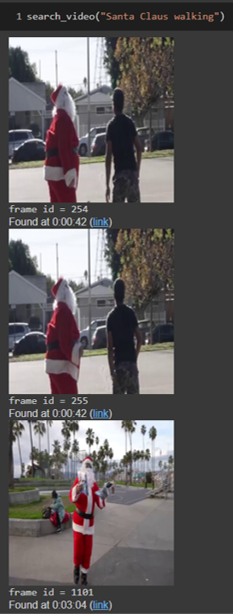
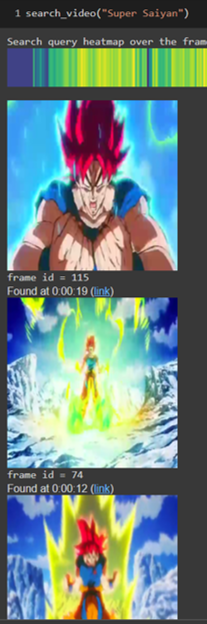
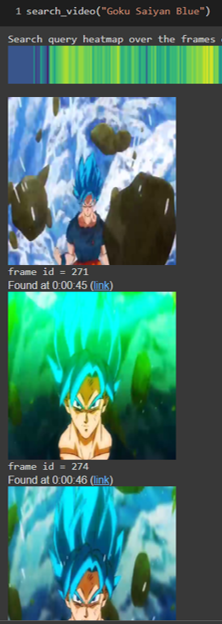
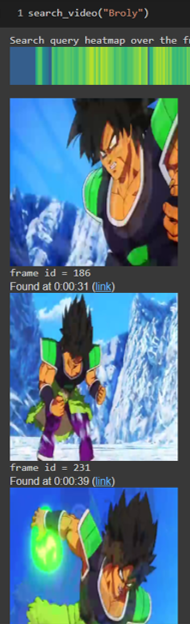
import plotly.express as px
import datetime
from IPython.core.display import HTML
def search_video(search_query, display_heatmap=False, display_results_count=3):
# Encode and normalize the search query using CLIP
with torch.no_grad():
text_features = model.encode_text(clip.tokenize(search_query, truncate=True).to(device))
text_features /= text_features.norm(dim=-1, keepdim=True)
# Compute the similarity between the search query and each frame using the Cosine similarity
similarities = (100.0 * video_features @ text_features.T)
values, best_photo_idx = similarities.topk(display_results_count, dim=0)
# Display the heatmap
if display_heatmap:
print(“Search query heatmap over the frames of the video:”)
fig = px.imshow(similarities.T.cpu().numpy(), height=50, aspect=‘auto’, color_continuous_scale=‘viridis’)
fig.update_layout(coloraxis_showscale=False)
fig.update_xaxes(showticklabels=False)
fig.update_yaxes(showticklabels=False)
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
fig.show()
print()
# Display the top 3 frames
for frame_id in best_photo_idx:
display(video_frames[frame_id])
# Find the timestamp in the video and display it
t = frame_id.cpu().numpy()[0]
print(‘frame id = %d’ % t)
seconds = round(t * N / fps)
display(HTML(f“Found at {str(datetime.timedelta(seconds=seconds))} (<a target=\“_blank\“ href=\“{video_url}&t={seconds}\“>link</a>)“))