Customer Segmentation?
การจัดกลุ่มลูกค้า (Customer Segmentation) คือการหาเกณฑ์หรือข้อกำหนดบางอย่างที่ตั้งขึ้นเพื่อแบ่งลูกค้าที่มีอยู่ของธุรกิจออกเป็นกลุ่มต่าง ๆ โดยจะใช้เกณฑ์หรือข้อกำหนดอะไรนั้นก็สามารถเลือกได้ตามความเหมาะสมของธุรกิจและเป้าหมายที่ต้องการ แต่ในบทความนี้จะกล่าวถึงการจัดกลุ่มลูกค้าที่มีอยู่ของธุรกิจ โดยจะใช้ข้อมูลจากการวิเคราะห์ RFM ในบทความที่แล้วมาแบ่งกลุ่มลูกค้าโดยใช้ K-Means Clustering ในการจัดกลุ่ม และวัตถุประสงค์ของการจัดกลุ่มลักษณะนี้ก็เพื่อให้ธุรกิจสามารถนำกลยุทธ์มาใช้ได้เจาะจงตรงเป้าเข้าถึงกลุ่มเป้าหมายได้ดียิ่งขึ้น
K-Means Clustering คืออะไร?
K-Means Clustering คือวิธีการแบบ Unsupervised Learning ใน Machine Learning มีวัตถุประสงค์หลักคือใช้เพื่อจัดกลุ่มข้อมูลขึ้นใหม่ โดยไม่จำเป็นต้องมีหมวดหมู่ใด ๆ กำกับก่อน แต่จะดูจากความคล้ายคลึงกันของข้อมูลแล้วจึงนำมาจัดกลุ่มเช่น ลูกค้าที่ใช้จ่ายเยอะและมีความถี่ในการใช้จ่ายสูงก็ควรอยู่ในกลุ่มเดียวกัน เป็นต้น (กล่าวง่าย ๆ คือแทนที่จะให้มนุษย์เป็นคนเขียนเกณฑ์สำหรับจัดกลุ่ม เราให้โมเดลจัดกลุ่มให้โดยใช้ข้อมูลเป็นหลักแทน) โดยพื้นฐานแล้วการจัดกลุ่มด้วย K-Means จะใช้การวัดระยะห่างของข้อมูล (ทั่วไปจะใช้ Euclidean Distance ยกกำลังสอง) และกำหนดจุด Centroid ขึ้นมาเป็นจุดกึ่งกลางของแต่ละกลุ่มจากนั้นจึงนำข้อมูลเข้าไปจัดตามกลุ่มตาม Centroid ที่มี และประเมินผลด้วยค่า Silhouette Score ยิ่งค่านี้เข้าใกล้ 1 แสดงว่าคลัสเตอร์ที่สร้างขึ้นมาสมาชิกมีความคล้ายคลึงกันมาก (ดี ลูกค้าที่ซื้อเหมือน ๆ กันก็ควรอยู่ด้วยกัน) หากเข้าใกล้ -1 แสดงว่าสมาชิกไม่คล้ายคลึงกัน (ไม่ดี) และวิธีการจัดกลุ่มสามารถทำได้ดังนี้
วิธีการจัดกลุ่มลูกค้าโดยใช้ข้อมูลจาก RFM Analysis
ต่อจากบทความที่แล้ว RFM คำนวณอย่างไร ทำอย่างไร ข้อมูลที่ได้จะนำมาใช้ต่อดังนี้
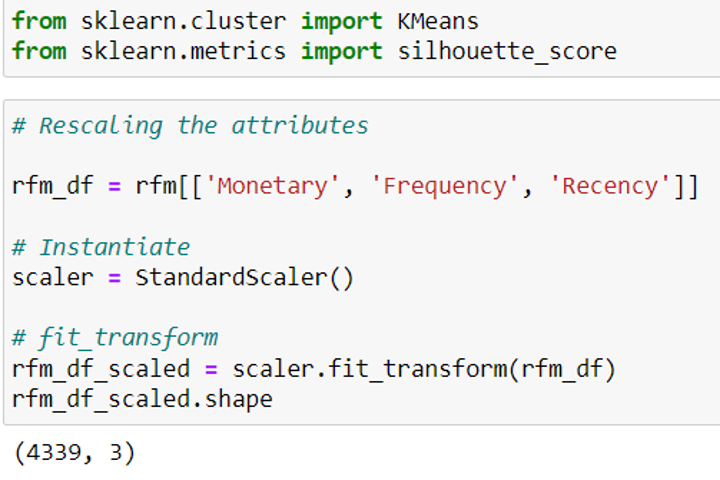
นำเข้า Library สำหรับทำ Machine Learning KMeans และ Metrics สำหรับประเมินผล Silhouette_score (จาก Scikit-Learn) และแปลงข้อมูล RFM ให้ค่าอยู่ในช่วงเดียวกันด้วย StandardScaler() (เพื่อให้ ML สามารถเรียนรู้ได้อย่างถูกต้องไม่เอนไปกับ Weigths ของข้อมูลมากเกิน)
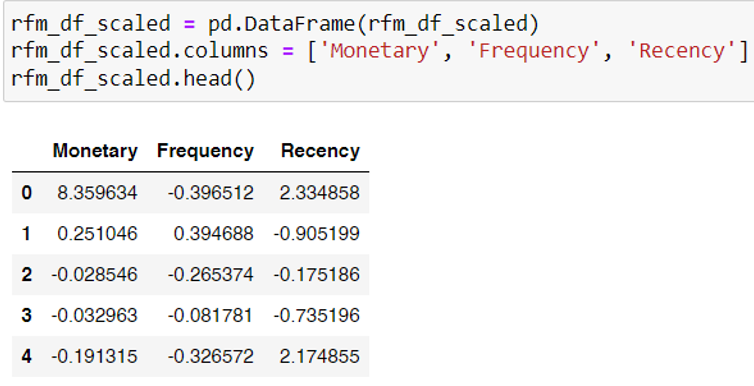
หลังจากปรับช่วงของข้อมูลแล้วตัวอย่างค่าจะเป็นดังในรูปข้างบน

เรียกใช้งาน K-Means Clustering โดยพารามิเตอร์ที่กำหนดหลัก ๆ จะเป็น
- n_clusters (จำนวนคลัสเตอร์ที่จะให้โมเดลจัดขึ้น) โดยจะมีกี่กลุ่มถึงจะดีนั้นเราสามารถใช้ Silhouette Score ในการเลือกได้ (แต่ก็อาจจะพิจารณาด้วยมนุษย์อีกที่ได้ว่าต้องการแบ่งกี่กลุ่ม)
- max_iter จำนวนรอบในการทำงานของ K-Means ในการทำงานแต่ละรอบ
- random_state ค่านี้กำหนดไว้เพื่อให้สามารถทำซ้ำและยังได้ค่าเดิม
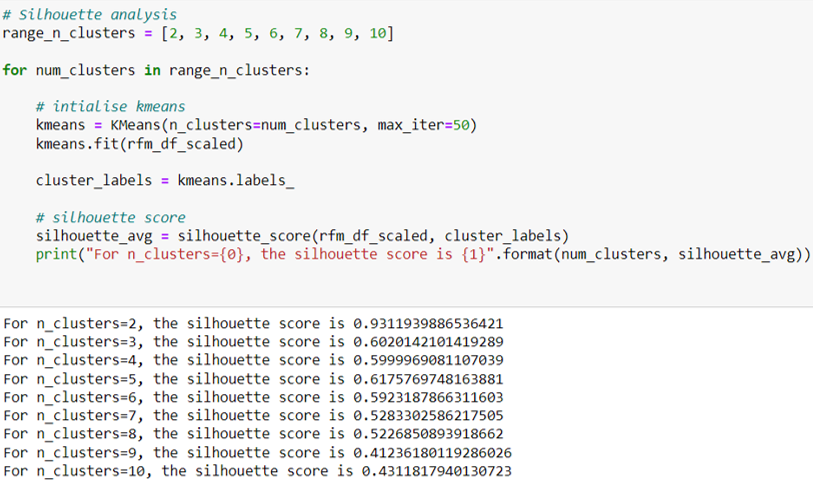
ในการทดลองหาว่าแบ่งเป็นกี่คลัสเตอร์จึงจะเหมาะสมนั้น เรากำหนดจำนวนคลัสเตอร์ที่ต้องการแบ่งขึ้นมาตั้งแต่ 2 ถึง 10 คลัสเตอร์ จากนั้นสร้างโมเดลตามแต่ละคลัสเตอร์และวัดผลด้วย Silhouette Score จะเห็นว่าหากแบ่งเป็น 2 คลัสเตอร์จะมีประสิทธิภาพที่ดีสุด (0.9311) แต่ถ้าหากต้องการมากกว่า 2 การแบ่งเป็น 5 คลัสเตอร์จะให้ประสิทธิภาพที่ดีสุด (0.6175)
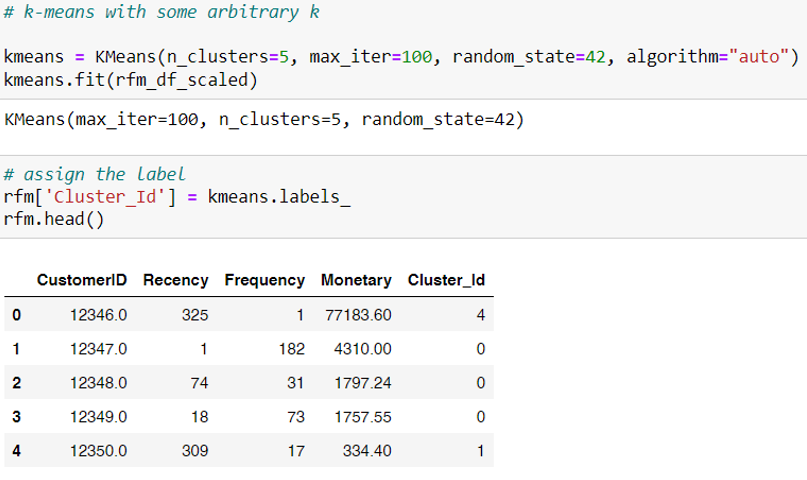
เทรนโมเดลอีกครั้งด้วยจำนวนคลัสเตอร์ 5 คลัสเตอร์ จากนั้นนำผลลัพธ์ที่ได้ลงไปเก็บในชุดข้อมูลเพื่อให้สามารถจัดกลุ่มได้ (ข้อมูล Map กันด้วย Index เนื่องจากเราไม่มีการสลับลำดับของข้อมูลเลย)
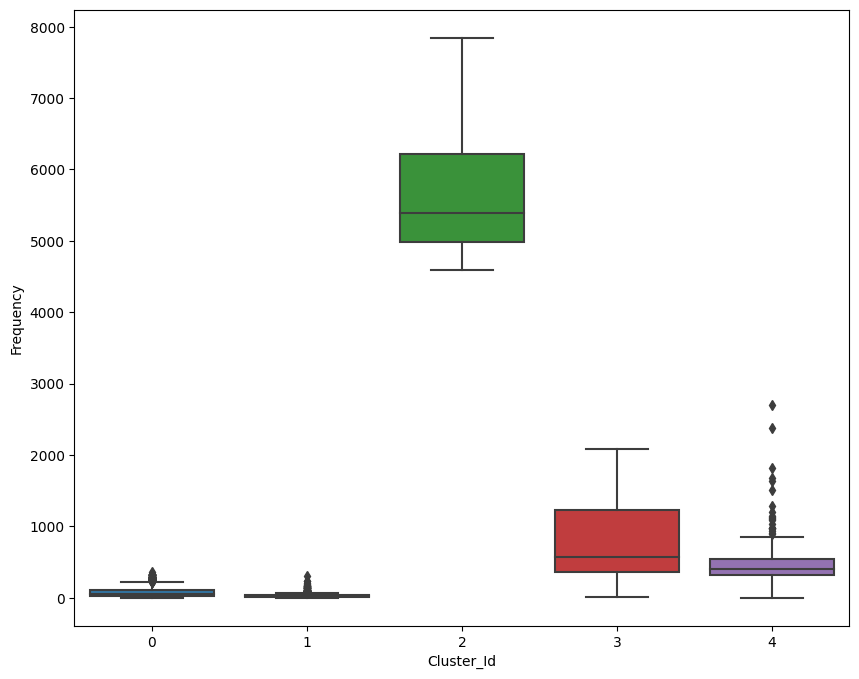
เรียกดูข้อมูลลูกค้า โดยดูว่าแต่ละกลุ่มที่จัดขึ้นมีความถี่ในการใช้จ่ายเป็นอย่างไรบ้าง
- กลุ่มแรก (0) มีความถี่ในการใช้จ่ายต่ำมาก
- กลุ่มสอง (1) มีความถี่ในการใช้จ่ายต่ำมาก
- กลุ่มสาม (2) มีความถี่ในการใช้จ่ายสูงมาก
- กลุ่มสี่ (3) มีความถี่ในการใช้จ่ายต่ำ
- กลุ่มห้า (4) มีความถี่ในการใช้จ่ายต่ำ
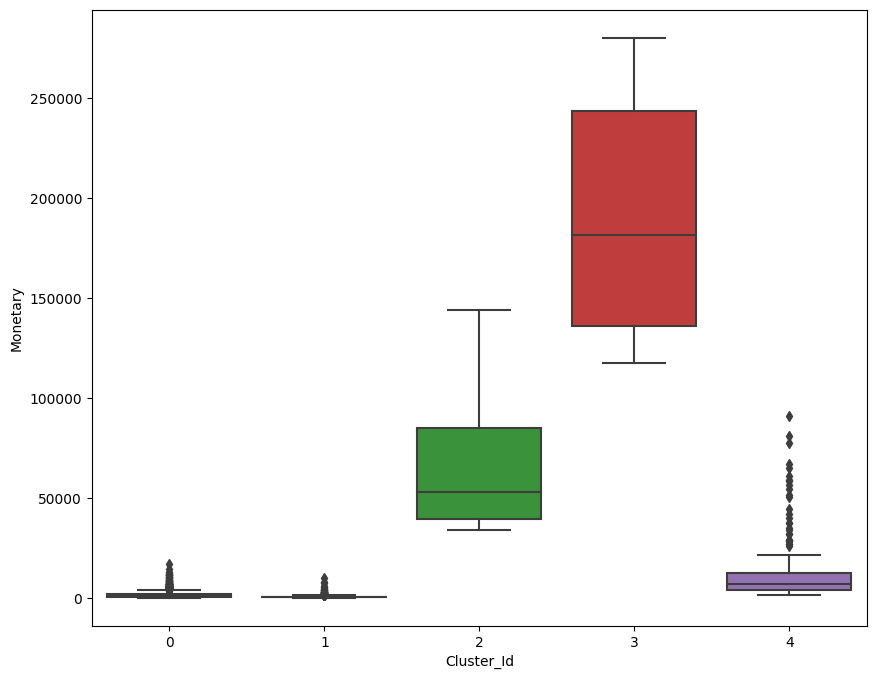
เรียกดูข้อมูลลูกค้า โดยดูว่าแต่ละกลุ่มที่จัดขึ้นมีมูลค่าการใช้จ่ายเป็นอย่างไรบ้าง
- กลุ่มแรก (0) มีมูลค่าในการใช้จ่ายต่ำมาก
- กลุ่มสอง (1) มีมูลค่าในการใช้จ่ายต่ำมาก
- กลุ่มสาม (2) มีมูลค่าในการใช้จ่ายปานกลาง
- กลุ่มสี่ (3) มีมูลค่าในการใช้จ่ายสูงมาก
- กลุ่มห้า (4) มีมูลค่าในการใช้จ่ายต่ำ
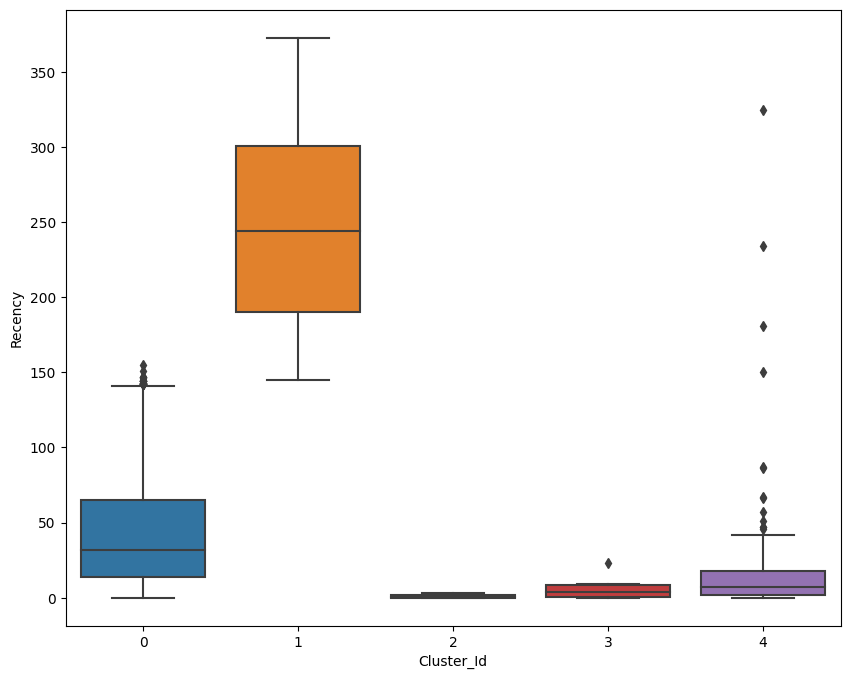
เรียกดูข้อมูลลูกค้า โดยดูว่าแต่ละกลุ่มที่จัดขึ้นมีความสดใหม่ (Recency) เป็นอย่างไรบ้าง
- กลุ่มแรก (0) มีความสดใหม่ปานกลาง
- กลุ่มสอง (1) มีความสดใหม่สูงมาก
- กลุ่มสาม (2) มีความสดใหม่ต่ำมาก
- กลุ่มสี่ (3) มีความสดใหม่ต่ำ
- กลุ่มห้า (4) มีความสดใหม่ต่ำ