Pytorch คืออะไร

Pytorch คือ Machine Learning Framework สามารถใช้ในการสร้างโมเดล Machine Learning, Neural Network ได้ครบจบในเฟรมเวิร์คนี้ ซึ่งค่อนข้างเหมาะมากในการใช้งานเชิงการทดลองหรือเชิงวิจัยเพราะมีเครื่องมือให้สามารถควบคุมการทำงานของโมเดลที่หลากหลายและใช้ง่ายอีกทั้งยังสามารถนำโมเดลไป Deploy ใช้งานจริงก็ทำได้เช่นกัน ในปัจจุบันเป็น Open Source ภายใต้ Linux Foundation แล้ว
วิธีการติดตั้ง
ก่อนเริ่มทำโปรเจค Python ทุกครั้งเราควรสร้าง Virtual Environment ก่อน โดยอ่านได้ที่ลิงก์นี้ และเมื่อสร้างเสร็จสิ้นและ Activate Environment แล้วให้ติดตั้ง Pytorch ภายใต้ Virtual Environment นั้น ๆ โดยเลือกตามเวอร์ชั่นและระบบปฏิบัติการตามที่ใช้งานได้เลย (ติดตั้ง) เช่นในที่นี้ใช้ระบบปฏิบัติการ Windows และต้องการที่จะติดตั้งด้วย Pip พร้อมกับใช้ CUDA เพื่อให้ประมวลผลบน GPU ได้เราก็จะทำการเลือกดังภาพด้านล่างนี้จากนั้นคัดลอกคำสั่งไปรันบน Command Prompt เพื่อติดตั้ง

เริ่มต้นใช้ Pytorch สร้างโมเดลจำแนกรูปภาพ

นำเข้า Library ที่จะต้องใช้งาน โดยแต่ละตัวมีหน้าที่หลัก ๆ ดังนี้
- torch สำหรับใช้งานฟังก์ชันต่าง ๆ ใน Pytorch
- nn สำหรับใช้สร้างโมเดล Neural Network
- torchvision.datasets สำหรับเตรียมข้อมูลรูปภาพที่มีให้เป็นชุดข้อมูลสำหรับใช้ในเฟรมเวิร์คนี้
- torchvision.transforms สำหรับแปลงรูปภาพให้เป็น Tensor หรือจะปรับขนาด ครอปรูปต่าง ๆ ก็ทำได้ด้วยโมดูลนี้เช่นกัน
- torch.utils.data.random_split ใช้สำหรับแบ่ง Datasets ที่เตรียมไว้ออกเป็นชุด train, test
- torch.utils.data.Dataloader ใช้สำหรับโหลดตัว Datasets ที่เตรียมไว้ให้พร้อมสำหรับนำไปประมวลผล
- torchvision.utils สำหรับใช้ฟังก์ชันอรรถประโยชน์ต่าง ๆ ที่ torchvision มีให้
- numpy สำหรับใช้คำนวณทั่วไป
- matplotlib.pyplot สำหรับแสดงรูปภาพ

เลือก device สำหรับประมวลผล โดยถ้ามี GPU พร้อมใช้งาน device จะเป็น cuda (เราสามารถเรียกดูชื่อของ device ได้ในที่นี้เป็น GeForce GTX 1660 Ti) แต่ถ้าหากไม่มี GPU ก็จะใช้เป็น CPU แทน
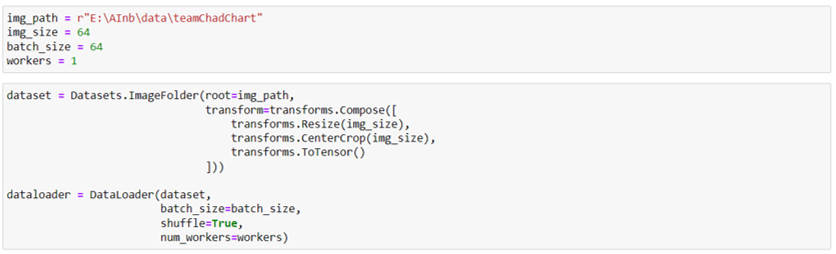
เตรียมตัวแปรที่จะต้องใช้งาน และโหลดชุดข้อมูลทั้งหมดเตรียมไว้
- เตรียม File Path ของโฟลเดอร์ที่เราเก็บรูปภาพไว้ (ในตัวอย่างนี้จะเก็บไว้ใน E:\AInb\data\teamChadChart ซึ่งภายในโฟลเดอร์นี้จะมีอีก 5 โฟลเดอร์แยกตามประเภทของรูปภาพได้แก่ flood, footpath, safety, traffic, trash)
- img_size เท่ากับ 64 เพื่อที่เราจะแปลงภาพให้มีขนาด 64*64 pixels
- batch_size เท่ากับ 64 เพื่อแบ่งข้อมูลเป็นชุดละ 64 รูปในตอนที่ปป้อนให้กับโมเดล ซึ่งจะกำหนดไว้ที่ DataLoader เลย
- workers เท่ากับ 1 ตั้งตามหน่วยประมวลผล GPU หรือ CPU ที่เรามี
สร้างชุดข้อมูลจากรูปภาพที่มี
- Datasets.ImageFolder ใช้สำหรับสร้างชุดข้อมูลรูปภาพให้กับ torchvision โดยข้อมูลรูปภาพจะต้องอยู่ในลักษณะที่เป็นโฟลเดอร์ย่อยที่แบ่งเป็นคลาส ๆ เช่น ในโฟลเดอร์ teamChadChart มีโฟลเดอร์ flood, footpath, safety, traffic, trash และในแต่ละโฟลเดอร์ก็จะมีรูปภาพอยู่จึงจะใช้งานฟังก์ชันนี้ได้
- root ให้ใส่ path ไปยังโฟลเดอร์ที่เก็บรวบรวมโฟลเดอร์รูปภาพไว้ทั้งหมด
- transform สามารถที่จะระบุได้ว่าจะทำอะไรบ้างโดยในที่นี้เราทำการ Resize ให้มีขนาด 64*64 จากนั้นครอปรูปภาพและแปลงข้อมูลเป็น Tensor เพื่อให้โมเดลนำไปประมวลผลได้
- Dataloader ใช้สำหรับโหลด Datasets เข้าไปเพื่อเตรียมใช้สำหรับฝึกสอนโมเดล
หากต้องการโหลดชุดข้อมูลในลักษณะอื่นสามารถศึกษาได้จากคู่มือของ Pytorch นี้

หากต้องการแบ่งชุดข้อมูลเป็นชุดฝึกสอนและตรวจสอบสามารถทำได้ดังนี้
- กำหนดขนาดของชุดข้อมูลฝึกสอน ในที่นี้ใช้ 80%
- กำหนดขนาดของชุดข้อมูลทดสอบ ในที่นี้ใช้ 20%
- ใช้ random_split เพื่อแบ่งชุดข้อมูลออกเป็นสองชุด โดยผ่านตัว datasets ตัวเต็มเข้าไป พร้อมกับขนาดที่ต้องการจะแบ่ง
- ทำการโหลดชุดข้อมูลฝึกสอน และชุดข้อมูลทดสอบด้วย DataLoader เหมือนเดิม
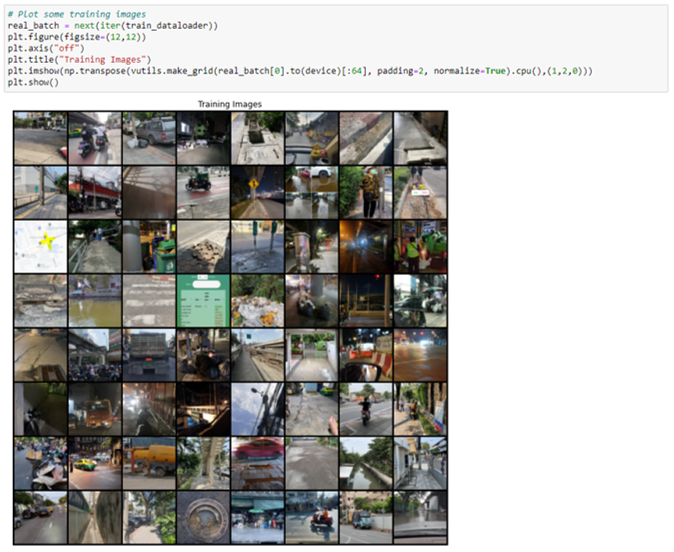
เรียกดูตัวอย่างรูปภาพจากชุดข้อมูลฝึกสอนจำนวน 64 ภาพ จะเห็นว่ามีบางรูปที่ไม่ใช่รูปปัญหาท้องถนนหากทำในโปรเจคจริงก็จะต้องจัดการรูปภาพเหล่านี้ด้วย
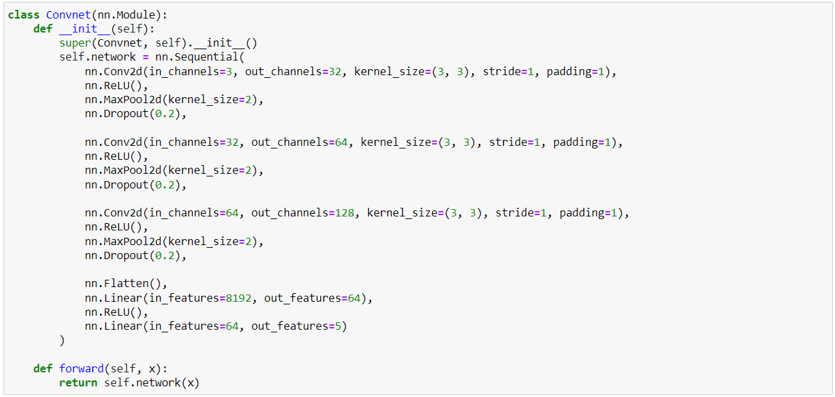
สร้างโมเดล Convnet (Convolution Neural Networks) ส่วนประกอบหลักของโมเดลนี้จะต้องมี Convolution Layers, Pooling Layers, และ Fully Connected Layers (หรือ Dense Layers) และการสร้างโมเดลใน Pytorch นั้นจะต้องสร้าง Class ที่ Inherited เอา nn.Module ของ Pytorch มาและจะต้องมีฟังก์ชัน __init__ กับ forward อยู่ข้างในเสมอ
- สร้าง def __init__ โดยรับค่าตัวมันเอง ดังในรูป และเรียกใช้ฟังก์ชัน super เพื่อบอกให้คลาสนี้ถูกเรียกใช้เมื่อใช้งานโมเดล ในส่วนของ Layers ต่าง ๆ เราจะใช้ nn.Sequential ในการประกอบชั้นต่าง ๆ ซึ่งเราจะสร้างโมเดล Convnet ที่ประกอบไปด้วยชั้น Convolution จำนวน 3 ชุดจากนั้นจึงเป็น Output Layers ในชั้นสุดท้าย (สำหรับโครงสร้างโมเดลต่าง ๆ ต้องไปศึกษาเอาเอง)
- สร้าง def forward โดยรับค่าตัวมันเองและค่าอินพุตท์ หน้าที่หลัก ๆ ของฟังก์ชันนี้คือเพื่อส่งข้อมูลเข้าไปประมวลผลในโมเดลที่เราได้สร้างไว้ด้านบน
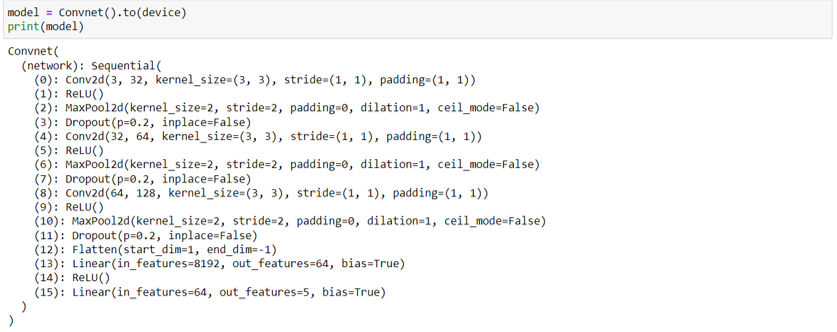
เรียกดูโครงสร้างของโมเดลที่ได้สร้างไว้ และส่งไปยัง device ที่จะใช้ประมวลผล
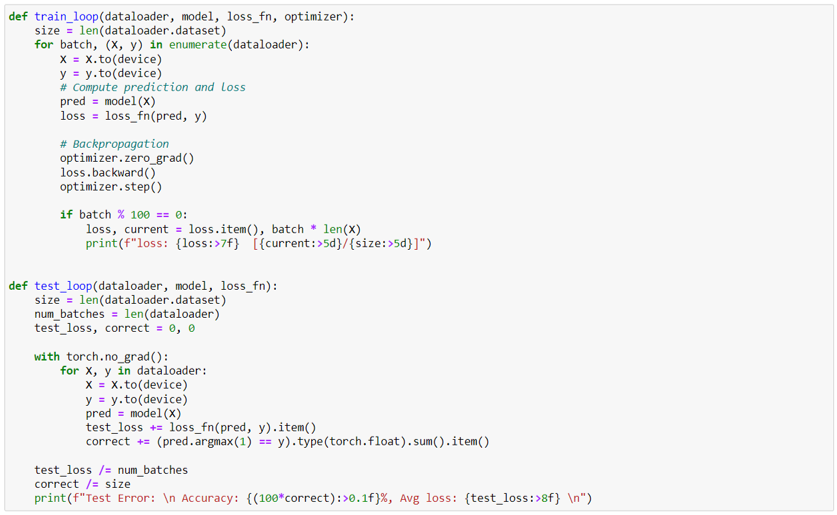
เตรียมฟังก์ชันสำหรับฝึกสอนและทดสอบโมเดล
- def train_loop ใช้สำหรับฝึกสอนโมเดล โดยจะรับค่าชุดข้อมูล, โมเดล, Loss Function, และ Optimizer ที่จะใช้งาน ส่วนการทำงานหลัก ๆ จะอยู่ใน for loop ซึ่งลูปนี้จะวนเข้าไปเอาข้อมูลใน dataloader ส่งข้อมูล Tensor ไปยัง device ที่ประมวลผล และเรียกโมเดลมาทำการประมวลผลและวัดค่า loss จากนั้นทำการ Optimize ด้วยฟังก์ชัน zero_grad, backward, และ step เพื่อให้โมเดลเรียนรู้ (ฟังก์ชันเหล่านี้จะช่วยปรับค่า Hyperparameters ของโมเดลให้ ถือเป็นข้อที่สะดวกมากของ Pytorch)
- def test_loop ใช้สำหรับประเมินผลการทำงานของโมเดล หลัก ๆ คือรับค่าชุดข้อมูล, โมเดล, และ Loss Function ที่ใช้จากนั้นนำไปลองจำแนกรูปภาพและคำนวนค่าความแม่นยำด้วย เมทริกซ์ Accuracy (ต่างกันที่ไม่ต้องทำ Optimize และมีการคำนวณ Accuracy)
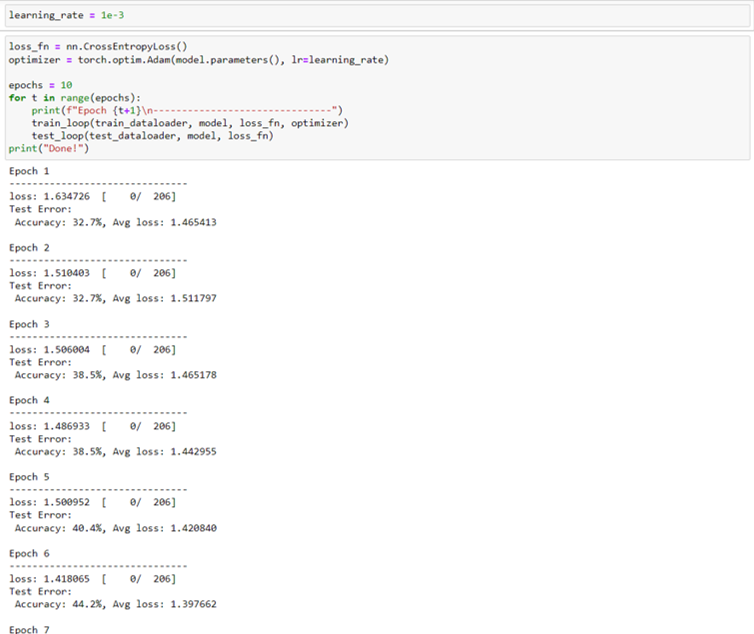
กำหนด Loss Function และ Optimizer ที่จะใช้งาน และเรียกใช้ฟังก์ชัน train_loop กับ test_loop เพื่อสอนโมเดล
- Loss Function ที่ใช้คือ CrossEntropy
- Optimizer ใช้ Adam โดยกำหนด Learning Rate ไว้ที่ 0.001
- จำนวนรอบในการฝึกสอนทั้งหมดคือ 10 รอบ
- เรียกใช้ train_loop โดยใส่ชุดข้อมูลสำหรับฝึกสอน, โมเดล, Loss Function, และ Optimizer เข้าไป
- เรียกใช้ test_loop เพื่อวัดผล
เมื่อฝึกสอนไปเรื่อย ๆ ค่า Loss ก็จะลดต่ำลง และค่าความแม่นยำก็จะเพิ่มสูงขึ้น
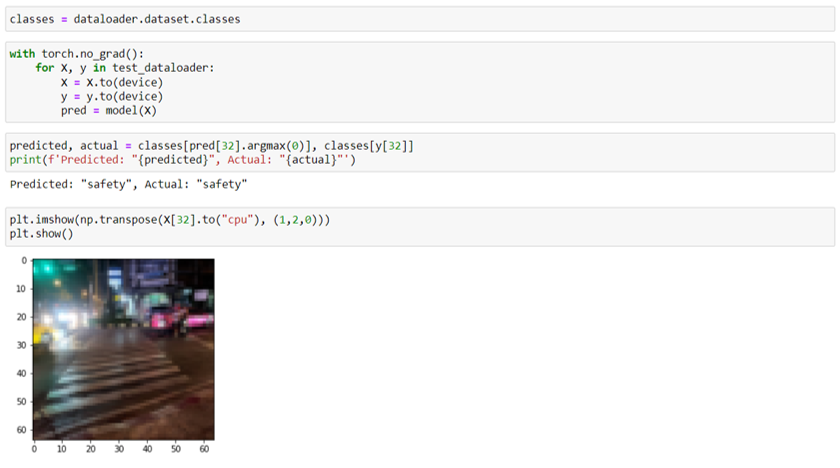
ทดสอบให้โมเดลจำแนกประเภทรูปภาพ โดยส่งรูปภาพทางม้าลายเข้าไปให้โมเดล โดยโมเดลจำแนกได้ว่าภาพนี้เป็นปัญหาด้าน safety ซึ่งตรงกับเฉลยของภาพนี้ที่เป็น safety (แต่จริง ๆ แล้วโมเดลนี้ยังทำงานผิดเยอะมากหากทำใช้จริงยังต้องปรับปรุงและเพิ่มการฝึกสอนอีกเยอะครับ) และเมื่อได้ผลลัพธ์ที่พึงพอใจแล้วนั้นก็ให้ Save Model เพื่อนำไปใช้ในงานอื่น ๆ ต่อไป วิธีการบันทึกและเรียกใช้โมเดลสามารถดูได้ที่นี่


